“As empresas devem adotar decisões mais automatizadas sempre que possível. É aqui que se encontram os maiores retornos do marketing de IA.”
Mais um post sobre Inteligência Artificial (IA) aplicada aos negócios, desta vez com foco em Marketing, fornecendo um framework que facilita o entendimento do planejamento aos gestores de marketing e outros interessados em IA.
Os diretores de marketing estão adotando cada vez mais a Inteligência Artificial:
Uma análise de 2018 da McKinsey de mais de 400 casos de uso avançados mostrou que o marketing era o domínio em que a IA contribuiria com o maior valor.
Uma pesquisa de agosto de 2019 da American Marketing Association revelou que a implementação de IA havia aumentado 27% no ano e meio anterior.
E uma pesquisa global da Deloitte em 2020 com os primeiros a adotar a IA mostrou que três dos cinco principais objetivos da IA eram orientados para o mercado: aprimorar produtos e serviços existentes, criar novos produtos e serviços e aprimorar os relacionamentos com os clientes.
Muitas empresas agora usam IA para lidar com tarefas restritas, como:
publicação de anúncios digitais (também conhecido como “compra programática”);
auxiliar em tarefas amplas, como aumentar a precisão das previsões (pense nas previsões de vendas); e
aumentar os esforços humanos em tarefas estruturadas, como atendimento ao cliente.
As empresas também empregam IA em todas as fases da jornada do cliente
Quando os clientes em potencial estão na fase de “consideração” e pesquisando um produto, a IA direcionará os anúncios para eles e pode ajudar a orientá-los na pesquisa.
Vê-se isso acontecer no varejista online de móveis Wayfair, que usa IA para determinar quais clientes têm maior probabilidade de ser persuadidos e, com base em seus históricos de navegação, escolhe produtos para mostrá-los.
E bots habilitados para IA de empresas como a Vee24 podem ajudar os profissionais de marketing a entender as necessidades dos clientes, aumentar seu envolvimento em uma pesquisa, empurrá-los na direção desejada, como uma página da web específica e, se necessário, conectá-los a um humano agente de vendas por chat, telefone, vídeo ou mesmo “co-navegação” – permitindo que um agente ajude o cliente a navegar em uma tela compartilhada.
A IA pode agilizar o processo de vendas usando dados extremamente detalhados sobre os indivíduos, incluindo dados de geolocalização em tempo real, para criar ofertas de produtos ou serviços altamente personalizadas. Mais tarde na jornada, a IA auxilia no upsell e na venda cruzada e pode reduzir a probabilidade de os clientes abandonarem seus carrinhos de compras digitais. Por exemplo, depois que um cliente preenche um carrinho, os bots de IA podem fornecer um depoimento motivador para ajudar a fechar a venda, como “Excelente compra! James de Vermont comprou o mesmo colchão”. Essas iniciativas podem aumentar as taxas de conversão cinco vezes ou mais.
Após a venda, os agentes de serviço habilitados para IA de empresas como Amelia (anteriormente IPsoft) e Interactions estão disponíveis 24 horas por dia, 7 dias por semana para fazer a triagem das solicitações dos clientes – e são capazes de lidar com volumes flutuantes de solicitações de serviço melhores do que os agentes humanos. Eles podem lidar com questões simples sobre, digamos, tempo de entrega ou agendamento de uma consulta e podem escalar questões mais complexas para um agente humano.
Em alguns casos, a IA auxilia os representantes humanos analisando o tom dos clientes e sugerindo respostas com diferenciais, orientando os agentes sobre a melhor forma de satisfazer as necessidades dos clientes ou sugerindo a intervenção de um supervisor.
O Framework
A IA de marketing pode ser categorizada de acordo com duas dimensões: nível de inteligência e se é autônomo ou parte de uma plataforma mais ampla. Algumas tecnologias, como chatbots ou motores de recomendação, podem cair em qualquer uma das categorias; é como eles são implementados em um aplicativo específico que determina sua classificação.
Vamos examinar os dois tipos de inteligência primeiro
Automação de tarefas. Esses aplicativos executam tarefas repetitivas e estruturadas que requerem níveis relativamente baixos de inteligência.
Eles são projetados para seguir um conjunto de regras ou executar uma determinada sequência de operações com base em uma determinada entrada, mas eles não podem lidar com problemas complexos, como solicitações de clientes diferenciadas. Um exemplo seria um sistema que envia automaticamente um e-mail de boas-vindas a cada novo cliente. Chatbots mais simples, como aqueles disponíveis através do Facebook Messenger e outros provedores de mídia social, também se enquadram esta categoria. Eles podem fornecer alguma ajuda aos clientes durante as interações básicas, levando os clientes a uma determinada árvore de decisão, mas eles não conseguem discernir a intenção dos clientes, oferecer respostas personalizadas ou aprender com as interações ao longo do tempo.
Aprendizado de máquina. Esses algoritmos são treinados usando grandes quantidades de dados para fazer previsões e decisões relativamente complexas, gerando modelos. Esses modelos podem reconhecer imagens, decifrar textos, segmentar clientes e antecipar como os clientes responderão a várias iniciativas, como promoções. O aprendizado de máquina já impulsiona a compra programática em publicidade online, mecanismos de recomendação de e-commerce e modelos de propensão de vendas em sistemas de gerenciamento de relacionamento com o cliente (CRM). Ele e sua variante mais sofisticada, aprendizado profundo, são as tecnologias mais avançadas em IA e estão rapidamente se tornando ferramentas poderosas de marketing. Dito isso, é importante esclarecer que os aplicativos de aprendizado de máquina existentes ainda executam tarefas restritas e precisam ser treinados com grandes quantidades de dados.
Agora, vamos considerar a IA independente versus a IA integrada
Aplicativos independentes. Esses são mais bem compreendidos como programas de IA claramente demarcados ou isolados. Eles são separados dos canais principais por meio dos quais os clientes aprendem, compram ou obtêm suporte para usar as ofertas de uma empresa ou os canais que os funcionários usam para comercializar, vender ou prestar serviços a essas ofertas. Simplificando, os clientes ou funcionários precisam fazer uma viagem especial além desses canais para usar a IA.
Considere o aplicativo de descoberta de cores criado por Behr, a empresa de tintas. Usando o processamento de linguagem natural do IBM Watson e os recursos do Tone Analyzer (que detectam emoções no texto), a O aplicativo oferece várias recomendações de cores de pintura personalizadas da Behr que são baseadas no humor que os consumidores desejam para seu espaço. Os clientes usam o aplicativo para selecionar duas ou três cores para o cômodo que pretendem pintar. A venda real de tinta é então executada fora do aplicativo, embora permita uma conexão para fazer o pedido da Home Depot.
Aplicativos integrados. Incorporado em sistemas existentes, estas aplicações IA geralmente são menos visíveis aos clientes, profissionais de marketing e vendedores que os utilizam do que os aplicativos independentes. Por exemplo, o aprendizado de máquina que toma decisões em fração de segundo sobre quais anúncios digitais oferecer aos usuários é integrado a plataformas que lidam com todo o processo de compra e colocação de anúncios.
O aprendizado de máquina integrado da Netflix oferece recomendações de vídeo aos clientes há mais de uma década; suas seleções simplesmente aparecem no menu de ofertas que os usuários veem quando acessam o site. Se o mecanismo de recomendação fosse independente, eles precisariam acessar um aplicativo dedicado e solicitar sugestões.
Os fabricantes de sistemas de CRM incorporam cada vez mais recursos de aprendizado de máquina em seus produtos. Na Salesforce, o pacote Sales Cloud Einstein tem vários recursos, incluindo um sistema de pontuação de leads baseado em IA que classifica automaticamente os leads de clientes B2B pela probabilidade de compra.
Fornecedores como a Cogito, que vende IA que treina vendedores de call center, também integram seus aplicativos ao sistema CRM da Salesforce.
Combinando os dois tipos de inteligência
Combinar os dois tipos de inteligência e dois tipos de estrutura produz os quatro quadrantes do framework: aplicativos autônomos de aprendizado de máquina, aplicativos integrados de aprendizado de máquina, aplicativos autônomos de automação de tarefas e aplicativos integrados de automação de tarefas.
Entender em quais quadrantes os aplicativos se enquadram pode ajudar os profissionais de marketing a planejar e sequenciar a introdução de novos usos.
Uma abordagem escalonada
Acredita-se que os profissionais de marketing verão o maior valor ao buscar aplicativos integrados de aprendizado de máquina, embora sistemas simples baseados em regras e de automação de tarefas possam aprimorar processos altamente estruturados e oferecer potencial razoável para retornos comerciais.
Observe, no entanto, que hoje em dia a automação de tarefas está cada vez mais combinada com aprendizado de máquina – para extrair dados-chave de mensagens, tomar decisões mais complexas e personalizar comunicações – um híbrido que abrange quadrantes.
Os aplicativos independentes continuam a ter seu lugar onde a integração é difícil ou impossível, embora haja limites para seus benefícios. Portanto, recomenda-se os profissionais de marketing a, com o tempo, integrar a IA aos sistemas de marketing atuais, em vez de continuar com os aplicativos independentes. E, de fato, muitas empresas estão caminhando nessa direção geral; na pesquisa Deloitte de 2020, 74% dos executivos globais de IA concordaram que “a IA será integrada a todos os aplicativos corporativos dentro de três anos”.
Começando
Para empresas com experiência limitada em IA, uma boa maneira de começar é construindo ou comprando aplicativos simples baseados em regras.
Muitas empresas buscam uma abordagem “rastejar-caminhar-correr”, começando com um aplicativo independente de automação de tarefas não voltado para o cliente, como aquele que orienta os agentes de serviço humano que se envolvem com os clientes.
Depois que as empresas adquirem habilidades básicas de IA e uma abundância de dados de mercado e clientes, elas podem começar a mudar da automação de tarefas para o aprendizado de máquina. Um bom exemplo do último é a IA de seleção de roupas da Stitch Fix, que ajuda seus estilistas a selecionar ofertas para os clientes e se baseia em suas preferências de estilo autorrelatadas, os itens que mantêm e devolvem, e os comentários que fizeram.
Esses modelos se tornaram ainda mais eficazes quando a empresa começou a pedir aos clientes que escolhessem entre as fotos do Style Shuffle, criando uma fonte valiosa de novos dados.
Novas fontes de dados – como transações internas, fornecedores externos e até aquisições em potencial – são algo que os profissionais de marketing devem procurar constantemente, uma vez que a maioria dos aplicativos de IA, especialmente o aprendizado de máquina, exige grandes quantidades de dados de alta qualidade. Considere o modelo de precificação baseado em aprendizado de máquina que a empresa de fretamento de jato XO usou para aumentar seu EBITDA em 5%: A chave era acessar fontes externas para dados sobre o fornecimento de jatos particulares e fatores que afetam a demanda, como grandes eventos, a macroeconomia, a atividade sazonal e o clima. Os dados que o XO usa estão disponíveis publicamente, mas é uma boa ideia também buscar fontes proprietárias sempre que possível, porque os modelos que usam dados públicos podem ser copiados pelos concorrentes.
À medida que as empresas se tornam mais sofisticadas no uso da IA de marketing, muitas automatizam totalmente certos tipos de decisões, tirando totalmente os humanos do circuito. Com decisões repetitivas e de alta velocidade, como as exigidas para a compra de anúncios programáticos (em que os anúncios digitais são veiculados quase instantaneamente aos usuários), essa abordagem é essencial.
Em outros domínios, a IA só pode apresentar recomendações a uma pessoa diante de uma escolha – por exemplo, sugerir um filme a um consumidor ou uma estratégia a um executivo de marketing. Tomada de decisão humana é normalmente reservado para as questões mais importantes, como se deve continuar uma campanha ou aprovar um anúncio de TV caro.
As empresas devem tomar decisões mais automatizadas sempre que possível. Acredita-se que é aqui que os maiores retornos da IA de marketing serão encontrados.
Desafios e riscos
A implementação até mesmo dos aplicativos de IA mais simples pode apresentar dificuldades.
A IA de automação de tarefas autônoma, apesar de sua sofisticação técnica inferior, ainda pode ser difícil de configurar para fluxos de trabalho específicos e exige que as empresas adquiram habilidades de IA adequadas. Trazendo qualquer tipo de IA em um fluxo de trabalho exige integração cuidadosa de tarefas humanas e de máquina para que a IA aumente as habilidades das pessoas e não seja implantada de maneiras que criem problemas. Por exemplo, enquanto muitas organizações usam chatbots baseados em regras para automatizar o atendimento ao cliente, bots menos capazes podem irritar os clientes. Pode ser melhor ter esses bots ajudando agentes humanos ou conselheiros em vez de interagir com os clientes.
À medida que as empresas adotam aplicativos mais sofisticados e integrados, surgem outras considerações. Incorporar IA em plataformas de terceiros, em particular, pode ser complicado. Um caso em questão é oferecido pelo Olay Skin Advisor da Procter & Gamble, que usa aprendizado profundo para analisar selfies que os clientes tiraram, avaliar sua idade e tipo de pele e recomendar produtos apropriados. Ele está integrado a uma plataforma de e-commerce e fidelidade, Olay.com, e melhorou as taxas de conversão, taxas de rejeição e tamanhos médios de cesta em algumas geografias.
No entanto, tem sido mais difícil integrá-lo com lojas de varejo e Amazon, terceiros que respondem por uma alta porcentagem das vendas de Olay. O Skin Advisor não está disponível no extenso site da loja de Olay na Amazon, dificultando a capacidade da marca de oferecer uma experiência de cliente assistida por IA integrada.
Finalmente, as empresas devem manter os interesses dos clientes em mente. Quanto mais inteligentes e integrados os aplicativos de IA, mais preocupações os clientes podem ter sobre privacidade, segurança e propriedade de dados. Os clientes podem ficar nervosos com os aplicativos que capturam e compartilham dados de localização sem seu conhecimento ou sobre alto-falantes inteligentes que podem estar espionando. Em geral, os consumidores mostraram disposição (até mesmo ânsia) de trocar alguns dados pessoais e privacidade em troca do valor que aplicativos inovadores podem oferecer.
As preocupações com aplicativos de IA como Alexa parecem ser diminuídas pela apreciação de seus benefícios. Portanto, a chave para os profissionais de marketing, à medida que expandem a inteligência e o alcance de sua IA, é garantir que seus controles de privacidade e segurança sejam transparentes, que os clientes tenham algo a dizer sobre como seus dados são coletados e usados e que obtenham valor justo da empresa em troca. Para garantir essas proteções e manter a confiança dos clientes, os CMOs devem estabelecer conselhos de revisão de ética e privacidade – comespecialistas em marketing e jurídicos – para examinar projetos de IA, especialmente aqueles que envolvem dados de clientes ou algoritmos que podem ser tendenciosos, como pontuação de crédito.
Considerações finais
Enquanto marketing, IA é uma grande promessa, pede-se aos CMOs que sejam realistas sobre suas capacidades atuais. Apesar do hype, a IA ainda pode realizar apenas tarefas específicas, não executar uma função ou processo de marketing inteiro. No entanto, já está oferecendo benefícios substanciais aos profissionais de marketing – e de fato é essencial em algumas atividades de marketing – e seus recursos estão crescendo rapidamente.
Acredita-se que a IA acabará transformando o marketing, mas é uma jornada que levará um bom tempo. A função de marketing e as organizações que a suportam, TI em particular, precisarão prestar atenção a longo prazo para construir recursos de IA e abordar quaisquer riscos potenciais. Pede-se aos profissionais de marketing que comecem a desenvolver uma estratégia hoje para aproveitar as vantagens da funcionalidade atual da IA e seu provável futuro.
Planejar o uso da IA é desafiador, mas viável com o apoio de bons parceiros.
Conte comigo em seus projetos. Sobre mim: aqui. Contato: aqui.
Este texto partiu do conteúdo traduzido e adaptado com base no post original em inglês, da Harvard Business Review (HBR) “How to Design an AI Marketing Strategy”, de Thomas H. Davenport, Abhijit Guha e Dhruv Grewal (2021)
“A inteligência artificial é a elucidação do processo de aprendizado humano, a quantificação do processo de pensamento humano, a explicação do comportamento humano e a compreensão do que torna a inteligência possível. É o passo final do homem para se entender, e espero participar dessa nova, mas promissora ciência.” – Kai-Fu Lee (1983), autor do livro “AI Super-Powers: China, Silicon Valley and the New World Order” (New York Times bestseller), lançado em 2018.
“Inteligência Artificial (definição): A teoria e o desenvolvimento de sistemas computacionais capazes de realizar tarefas que normalmente requerem inteligência humana, como percepção visual, reconhecimento de fala, tomada de decisão e tradução entre idiomas.” – Dicionário Oxford
Esta série de artigos que eu tenho postado sobre o uso da IA em Negócios fornece a líderes, gestores e profissionais de negócios uma base de conhecimentos que facilita o entendimento do tema e os prepara para uma relação mais próxima com os profissionais de tecnologia e realização de projetos em suas empresas.
Como liderar sua empresa na era da IA
A tecnologia de IA (Inteligência Artificial) agora está pronta para transformar todos os setores, assim como a eletricidade fez 100 anos atrás. Espera-se que até 2030, forneça um crescimento econômico estimado em 13 trilhões de dólares. Embora já tenha criado um tremendo valor em empresas líderes em tecnologia, como Google, Baidu, Microsoft e Facebook, muitas das ondas adicionais de criação de valor estão indo além do setor de software.
Este artigo trata-se de um pequeno guia de orientação para transformação da empresa utilizando o potencial da Inteligência Artificial (IA). Trata-se da tradução e adaptação do texto original que é baseado em insights obtidos de Andrew Ng, da empresa Landing AI, ao liderar equipes do Google Brain e o Baidu AI Group, onde ele desempenhou papéis de liderança na transformação do Google e do Baidu em grandes empresas de IA.
Observação: O guia é direcionado à grandes empresas, mas que pode ser adaptado para uso em empresas menores, com o uso de plataformas de computação cognitiva, inteligência artificial e aprendizado de máquina automatizado (AutoML) como serviço em nuvem – o que requer menos infraestrutura e profissionais para começar.
Veja as recomendações em 5 passos:
1. Execute projetos piloto para ganhar impulso
É mais importante que seus primeiros projetos de IA sejam bem-sucedidos do que os projetos de IA mais valiosos. Eles devem ser significativos o suficiente para que os sucessos iniciais ajudem sua empresa a se familiarizar com a IA e também convença outras pessoas da empresa a investir em outros projetos de IA; eles não devem ser tão pequenos que outros considerem triviais. O importante é fazer o volante girar para que sua equipe de IA possa ganhar impulso.
Características sugeridas para os primeiros projetos de IA:
Idealmente, deve ser possível para uma equipe de IA nova ou externa (que pode não ter profundo conhecimento de domínio sobre sua empresa) fazer parceria com suas equipes internas (que têm profundo conhecimento de domínio) e criar soluções de IA que comecem a mostrar tração em 6-12 meses.
O projeto deve ser tecnicamente viável. Muitas empresas ainda estão iniciando projetos que são impossíveis usando a tecnologia de IA de hoje; ter engenheiros de IA confiáveis fazendo a devida diligência em um projeto antes do início aumentará sua convicção em sua viabilidade.
Tenha um objetivo claramente definido e mensurável que crie valor comercial.
Sucesso em um primeiro projeto piloto, trará a confiança necessária para projetos maiores e mais complexos.
2. Crie uma equipe interna de IA
Embora parceiros terceirizados com profundo conhecimento técnico em IA possam ajudá-lo a ganhar esse impulso inicial mais rapidamente, a longo prazo será mais eficiente executar alguns projetos com uma equipe interna de IA. Além disso, você desejará manter alguns projetos dentro da empresa para construir uma vantagem competitiva mais exclusiva.
É importante ter a adesão da liderança para construir essa equipe interna. Durante a ascensão da internet, a contratação de um CIO foi um ponto de virada para muitas empresas terem uma estratégia coesa de uso da internet. Em contraste, as empresas que realizaram muitos experimentos independentes – desde marketing digital até experimentos de ciência de dados e lançamentos de novos sites – não conseguiriam alavancar os recursos da Internet se esses pequenos projetos-piloto não conseguissem escalar para transformar o resto da empresa.
Na era da IA, um momento chave para muitas empresas será novamente a formação de uma equipe de IA centralizada que possa ajudar toda a empresa. Essa equipe de IA pode ficar sob a função de CTO, CIO ou CDO (Chief Data Officer ou Chief Digital Officer) se tiver o conjunto de habilidades certo. Também poderia ser liderado por um CAIO (Chief AI Officer) dedicado. As principais responsabilidades da unidade de IA são:
Construir uma capacidade de IA para dar suporte a toda a empresa.
Executar uma sequência inicial de projetos multifuncionais para dar suporte a diferentes divisões/unidades de negócios com projetos de IA. Depois de concluir os projetos iniciais, configurar processos repetidos para entregar continuamente uma sequência de projetos valiosos de IA.
Desenvolver padrões consistentes para recrutamento e retenção.
Desenvolver plataformas para toda a empresa que sejam úteis para várias divisões/unidades de negócios e que provavelmente não sejam desenvolvidas por uma divisão individual. Por exemplo, considere trabalhar com o CTO/CIO/CDO para desenvolver padrões de armazenamento de dados unificados.
Muitas empresas são organizadas com várias unidades de negócios subordinadas ao CEO. Com uma nova unidade de IA, você será capaz de integrar o talento de IA às diferentes divisões para conduzir projetos multifuncionais.
Novas descrições de cargos e novas organizações de equipe surgirão. Uma maneira de organizar o trabalho de equipes é em funções como engenheiro de aprendizado de máquina, engenheiro de dados, cientista de dados e gerente de produto de IA, o que é diferente da era pré-IA. Um bom líder de IA poderá aconselhá-lo sobre a configuração dos processos corretos.
Atualmente, há uma guerra por talentos de IA e, infelizmente, a maioria das empresas terá dificuldade em contratar um estudante ou graduado em doutorado em IA de Stanford, por exemplo. Como a guerra de talentos é basicamente de soma zero no curto prazo, trabalhar com um parceiro de recrutamento que pode ajudá-lo a construir uma equipe de IA.
3. Forneça amplo treinamento de IA
Nenhuma empresa hoje tem talento interno de IA suficiente. Enquanto as reportagens da mídia sobre altos salários de IA são exageradas (os números citados na imprensa tendem a ser discrepantes), é difícil encontrar talento em IA. Felizmente, com o aumento do conteúdo digital, incluindo MOOCs (cursos online abertos e massivos), como Coursera, e-books e vídeos do YouTube, é mais econômico do que nunca treinar muitos funcionários em novas habilidades, como IA. O CLO inteligente (Chief Learning Officer) sabe que seu trabalho é selecionar, em vez de criar conteúdo, e então estabelecer processos para garantir que os funcionários concluam as experiências de aprendizado.
Se você tiver orçamento para contratar consultores, o conteúdo presencial deve complementar o conteúdo online. Isso é chamado de pedagogia da “sala de aula invertida” que resulta em aprendizado mais rápido e uma experiência de aprendizado mais agradável. Contratar alguns especialistas em IA para fornecer algum conteúdo pessoalmente também pode ajudar a motivar seus funcionários a aprender essas técnicas de IA.
A IA proverá novos empregos diferentes. Você deve dar a todos o conhecimento de que precisam para se adaptar às suas novas funções na era da IA. A consulta com um especialista permitirá que você desenvolva um currículo personalizado para sua equipe. No entanto, um plano de educação inicial pode ser assim:
3.1. Executivos e líderes empresariais seniores: (⩾4 horas de treinamento)
META – Permita que os executivos entendam o que a IA pode fazer pela sua empresa, comecem a desenvolver a estratégia de IA, tomem decisões de alocação de recursos apropriadas e colaborem sem problemas com uma equipe de IA que está apoiando projetos de IA valiosos. CURRÍCULO:
Compreensão empresarial básica da IA, incluindo tecnologia básica, dados e o que a IA pode e não pode fazer.
Compreensão do impacto da IA na estratégia corporativa.
Estudos de caso sobre aplicativos de IA para setores adjacentes ou para o seu setor específico.
3.2. Líderes de divisões que realizam projetos de IA: (⩾12 horas de treinamento)
META – Os líderes de divisão devem ser capazes de definir a direção dos projetos de IA, alocar recursos, monitorar e acompanhar o progresso e fazer as correções necessárias para garantir a entrega bem-sucedida do projeto. CURRÍCULO:
Compreensão empresarial básica da IA, incluindo tecnologia básica, dados e o que a IA pode e não pode fazer.
Conhecimento técnico básico de IA, incluindo as principais classes de algoritmos e seus requisitos.
Compreensão básica do fluxo de trabalho e processos de projetos de IA, funções e responsabilidades em equipes de IA e gerenciamento de equipe de IA.
3.3. Estagiários de engenharia de IA: (⩾100 horas de treinamento)
META – Engenheiros de IA recém-treinados devem ser capazes de coletar dados, treinar modelos de IA e entregar projetos de IA específicos. CURRÍCULO:
Profundo conhecimento técnico de machine learning e deep learning; compreensão básica de outras ferramentas de IA.
Compreensão das ferramentas disponíveis (código aberto e de terceiros) para construir sistemas de IA e dados.
Capacidade de implementar o fluxo de trabalho e os processos das equipes de IA.
Além disso: educação contínua para manter-se atualizado com a evolução da tecnologia de IA
4. Desenvolva uma estratégia de IA
Uma estratégia de IA orientará sua empresa para a criação de valor e, ao mesmo tempo, construirá fossos defensáveis. Assim que as equipes começarem a ver o sucesso dos projetos iniciais de IA e formar uma compreensão mais profunda da IA, você poderá identificar os lugares onde a IA pode criar mais valor e concentrar recursos nessas áreas.
Alguns executivos pensarão que desenvolver uma estratégia de IA deve ser o primeiro passo. A experiência diz que a maioria das empresas não será capaz de desenvolver uma estratégia de IA ponderada até que tenha alguma experiência básica com IA, que o progresso parcial nas etapas 1 a 3 fornecerá.
A maneira como você constrói fossos defensáveis também está evoluindo com a IA. Aqui estão algumas abordagens a serem consideradas:
Crie vários ativos de IA difíceis que estejam amplamente alinhados com uma estratégia coerente: a IA está permitindo que as empresas construam vantagens competitivas exclusivas de novas maneiras. Os escritos seminais de Michael Porter sobre estratégia de negócios mostram que uma maneira de iniciar um negócio defensável é construir vários ativos difíceis que estão amplamente alinhados com uma estratégia coerente. Assim, torna-se difícil para um concorrente replicar todos esses ativos simultaneamente.
Aproveite a IA para criar uma vantagem específica para o seu setor: em vez de tentar competir “geralmente” em IA com empresas líderes de tecnologia, como o Google, recomendo tornar-se uma empresa líder de IA em seu setor, onde o desenvolvimento de recursos exclusivos de IA permitirá você para obter uma vantagem competitiva. Como a IA afeta a estratégia da sua empresa será específica do setor e da situação.
Desenhe estratégias alinhadas com o ciclo de feedback positivo do “círculo virtuoso da IA”: em muitos setores, veremos o acúmulo de dados levando a um negócio defensável:
Por exemplo, os principais mecanismos de pesquisa da Web, como Google, Baidu, Bing e Yandex, têm um enorme ativo de dados mostrando quais links um usuário clica após diferentes consultas de pesquisa. Esses dados ajudam as empresas a criar um produto de mecanismo de pesquisa mais preciso (A), o que, por sua vez, as ajuda a adquirir mais usuários (B), o que, por sua vez, resulta em ter ainda mais dados de usuários (C). Esse ciclo de feedback positivo é difícil aos concorrentes invadirem.
Os dados são um ativo fundamental para os sistemas de IA. Assim, muitas grandes empresas de IA também têm uma estratégia de dados sofisticada. Os principais elementos da sua estratégia de dados podem incluir:
Aquisição de dados estratégicos: sistemas úteis de IA podem ser construídos com qualquer ponto de 100 dados (“small data”) a 100.000.000 pontos de dados (“big data”), e ter mais dados é melhor. As equipes de IA estão usando estratégias muito sofisticadas e de vários anos para adquirir dados, e estratégias específicas de aquisição de dados são específicas do setor e da situação. Por exemplo, o Google e o Baidu têm vários produtos gratuitos que não monetizam, mas permitem que eles adquiram dados que podem ser monetizados em outros lugares.
Armazéns de dados unificados: se você tiver 50 bancos de dados diferentes sob o controle de 50 VPs ou divisões diferentes, será quase impossível para um engenheiro ou software de IA obter acesso a esses dados e “conectar os pontos”. Em vez disso, considere centralizar seus dados em um ou no máximo um pequeno número de data warehouses.
Reconhecer quais dados são valiosos e quais não são: não é verdade que ter muitos terabytes de dados automaticamente significa que uma equipe de IA poderá criar valor a partir desses dados. Esperar que uma equipe de IA crie valor magicamente a partir de um grande conjunto de dados é uma fórmula que vem com uma grande chance de falha. tragicamente alguns CEOs investirem demais na coleta de dados de baixo valor, ou mesmo adquirem uma empresa para seus dados apenas para perceber que os muitos terabytes de dados da empresa-alvo não são úteis. Evite esse erro trazendo uma equipe de IA no início do processo de aquisição de dados e permita que eles o ajudem a priorizar quais tipos de dados adquirir e salvar.
Criar efeito de rede e vantagens de plataforma: Finalmente, a IA também pode ser usada para construir fossos mais tradicionais. Por exemplo, plataformas com efeitos de rede são negócios altamente defensáveis. Eles geralmente têm uma dinâmica natural de “o vencedor leva tudo” que força as empresas a crescer rápido ou morrer. Se a IA permitir que você adquira usuários mais rapidamente do que seus concorrentes, ela poderá ser aproveitada para construir um fosso que seja defensável por meio da dinâmica da plataforma. Mais amplamente, você pode usar a IA como um componente-chave da estratégia de baixo custo, alto valor ou outras estratégias de negócios.
5. Desenvolva comunicações internas e externas
A IA afetará significativamente seus negócios. Na medida em que afeta seus principais interessados, você deve executar um programa de comunicação para garantir o alinhamento. Aqui está o que você deve considerar para cada público:
Relações com investidores: As principais empresas de IA, como Google e Baidu, agora são empresas muito mais valiosas, em parte por causa de seus recursos de IA e do impacto que a IA tem em seus resultados. Explicar uma tese clara de criação de valor para a IA em sua empresa, descrever seus crescentes recursos de IA e ter uma estratégia de IA ponderada ajudará os investidores a valorizar sua empresa adequadamente.
Relações Governamentais: Empresas em setores altamente regulamentados (carros autônomos, assistência médica) enfrentam desafios únicos para manter a conformidade. Desenvolver uma história de IA convincente que explique o valor e os benefícios que seu projeto pode trazer para um setor ou sociedade é um passo importante na construção de confiança e boa vontade. Isso deve ser combinado com comunicação direta e diálogo contínuo com os reguladores à medida que você lança seu projeto.
Educação do usuário: a IA provavelmente trará benefícios significativos para seus clientes, portanto, certifique-se de que as mensagens apropriadas de marketing e roteiro de produto sejam divulgadas.
Talento/Recrutamento: Devido à escassez de talentos de IA, uma marca forte do empregador terá um efeito significativo na sua capacidade de atrair e reter esse talento. Os engenheiros de IA querem trabalhar em projetos interessantes e significativos. Um esforço modesto para mostrar seus sucessos iniciais pode percorrer um longo caminho.
Comunicações Internas: Como a IA hoje ainda é pouco compreendida e a Inteligência Artificial Geral especificamente foi exagerada, há medo, incerteza e dúvida. Muitos funcionários também estão preocupados com o fato de seus empregos serem automatizados pela IA, embora isso varie muito de acordo com a cultura (por exemplo, esse medo aparece muito mais nos EUA do que no Japão). Comunicações internas claras, tanto para explicar a IA quanto para abordar as preocupações desses funcionários, reduzirão qualquer relutância interna em adotar a IA.
Uma nota histórica, importante para o seu sucesso
Compreender como a internet transformou as indústrias é útil para navegar na ascensão da IA. Há um erro que muitas empresas cometeram ao navegar na ascensão da internet que espero que você evite ao navegar na ascensão da IA.
Aprendemos na era da internet que: Shopping + Site ≠ empresa de internet
Mesmo que um shopping center construísse um site e vendesse coisas nele, isso por si só não transforma o shopping em uma verdadeira empresa de internet. O que define uma verdadeira empresa de internet é: você organizou sua empresa para fazer as coisas que a internet permite que você faça muito bem?
Por exemplo, empresas de internet se envolvem em testes A/B abrangentes, nos quais lançam rotineiramente duas versões de um site e mede qual funciona melhor. Uma empresa de internet pode até ter centenas de experimentos rodando ao mesmo tempo; isso é muito difícil de fazer com um shopping físico. As empresas de Internet também podem publicar um novo visual ou produto toda semana e, assim, aprender muito mais rápido do que um shopping center que atualiza seu design apenas uma vez por trimestre. As empresas de Internet têm descrições de cargos exclusivas para funções como gerente de produto e engenheiro de software, e essas funções têm fluxos de trabalho e processos exclusivos para o modo como trabalham em conjunto.
O aprendizado profundo, uma das áreas de IA que mais cresce, está mostrando paralelos com a ascensão da internet.
Hoje sabemos que: Qualquer empresa típica + tecnologia Deep Learning ≠ empresa de IA
Para que sua empresa se torne ótima em IA, você terá que organizá-la para fazer as coisas que a IA permite que você faça muito bem.
Para que sua empresa seja ótima em IA, você deve ter:
Recursos para executar sistematicamente vários projetos valiosos de IA: as empresas de IA têm tecnologia e talento terceirizados e/ou internos para executar sistematicamente vários projetos de IA que agregam valor direto ao negócio.
Compreensão suficiente da IA: Deve haver uma compreensão geral da IA, com processos apropriados para identificar e selecionar sistematicamente projetos valiosos de IA para trabalhar.
Direção estratégica: a estratégia da empresa está amplamente alinhada para ter sucesso em um futuro alimentado por IA.
Considerações finais
Um programa de transformação de IA pode levar de 2 a 3 anos, mas você deve esperar resultados concretos iniciais dentro de 6 a 12 meses. Ao investir em uma transformação de IA, você ficará à frente de seus concorrentes e aproveitará os recursos de IA para avançar significativamente em sua empresa.
Transformar sua empresa em uma empresa de IA é desafiador, mas viável com o apoio de bons parceiros.
Conte comigo em seus projetos. Sobre mim: aqui. Contato: aqui.
Este texto partiu do conteúdo traduzido e adaptado com base no post original em inglês “AI Transformation Playbook – How to lead your company into the AI era”-driven Strategy in Data and AI”, de Andrew Ng.
O objetivo deste artigo é apresentar resumidamente uma introdução a alguns dos componentes mais importantes da inteligência artificial, sob o ponto de vista técnico, porém voltado a lideres e gestores negócios e iniciantes no tema, considerando: o aprendizado de máquina (machine learning), a aprendizagem profunda (deep learning) e a aprendizagem por reforço (reinforcement learning).
Uma visão geral sobre o tema pode ser visualizada com este primeiro diagrama que mostra a Relação entre a Inteligência Artificial, Aprendizado de Máquina e Aprendizagem Profunda:
Arthur Samuel descreveu-o em 1959 como: “o campo de estudo que dá aos computadores a capacidade de aprender sem serem explicitamente programados”. Esta é uma definição mais antiga e informal.
Tom Mitchell fornece uma definição mais moderna: “Diz-se que um programa de computador aprende com a experiência E em relação a alguma classe de tarefas T e medida de desempenho P, se seu desempenho em tarefas em T, medido por P, melhora com a experiência E.”
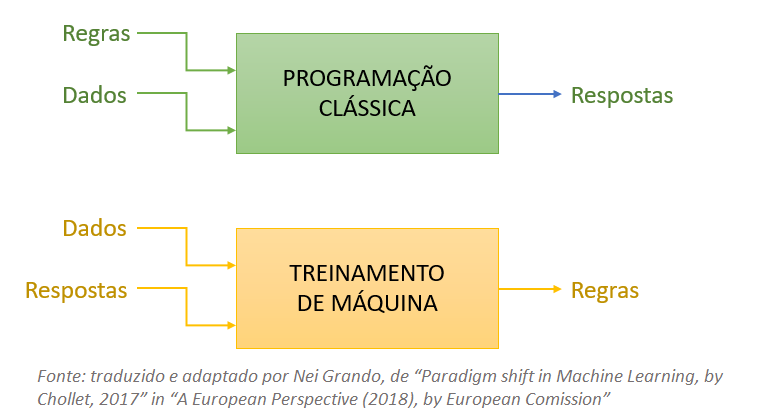
Esse diagrama simplificado apresenta a diferença básica entre a Programação Clássica de computadores versus a Aprendizagem de Máquina, como segue:
A seguir serão apresentados alguns diagramas simplificados (em inglês), obtidos do post “Machine Learning for Everyone“, com uma breve explicação (traduzida para o português).
Vale lembrar que o aprendizado de máquina depende essencialmente de três elementos: 1) Dados – com quantidade maior possível e qualidade o melhor de dados possível, relacionados ao problema que se deseja resolver; 2) Algoritmos – com o algoritmo ou conjunto deles, apropriado(s) para resolver o problema desejado; e 3) Parâmetros – usados no ajuste do tratamento dos dados.
Estes três elementos servirão durante o desenvolvimento para gerar um determinado Modelo de aprendizado que será utilizado para obter soluções a partir de novos dados em testes ou produção. Em alguns casos podem ser necessários ajustes nos parâmetros, mais e/ou melhores dados, ou até mesmo a troca do algoritmo por outro obtenha melhor precisão de resultados.
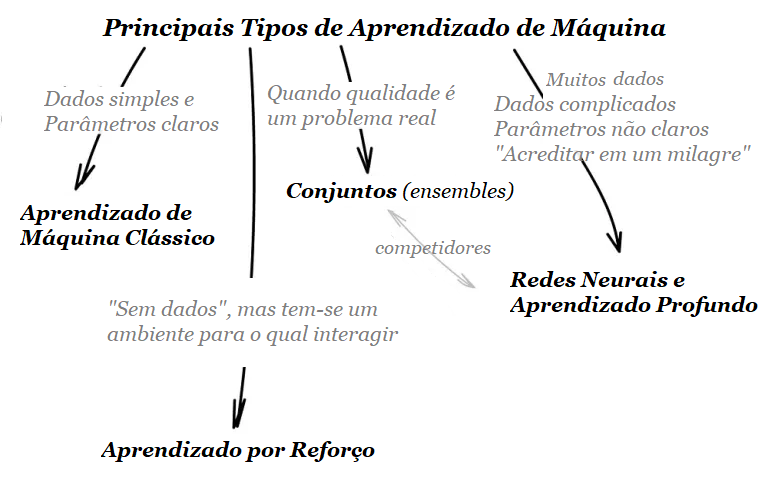
Os principais tipos de aprendizagem de máquina
É importante destacar que não há uma única maneira de resolver um problema no mundo da aprendizagem de máquinas, pois existem vários algoritmos adequados ao problema, assim precisa-se escolher qual deles se encaixa melhor. Quase tudo pode ser resolvido com uma rede neural, por exemplo, mas nem sempre é a melhor solução, principalmente devido ao custo computacional.
Seguem quatro direções principais no aprendizado de máquina.
1 – Aprendizado de máquina clássico
Os primeiros métodos vieram da estatística pura nos anos 50. Eles resolviam tarefas matemáticas formais – procurando padrões em números, avaliando a proximidade dos pontos de dados e calculando as direções dos vetores.
Hoje em dia, metade da Internet funciona baseada nestes algoritmos. Quando se vê uma lista de artigos para “ler em seguida” ou o banco bloqueia o cartão de alguém em um posto de gasolina aleatório no meio do nada, provavelmente é o trabalho de um algoritmo de machine learning.
Empresas de tecnologia são grandes fãs de redes neurais, obviamente. Para elas, uma precisão de 2% é uma receita adicional de 2 bilhões. Mas quando você é pequeno, não faz sentido tanto esforço.
Há histórias de equipes gastando um ano em um novo algoritmo de recomendação para o site de comércio eletrônico, antes de descobrir que 99% do tráfego vem de mecanismos de pesquisa. Seus algoritmos eram inúteis. A maioria dos usuários nem abriu a página principal.
Apesar da popularidade, as abordagens clássicas são tão naturais que você poderia facilmente explicá-las a uma criança. Elas são como aritmética básica, as usamos todos os dias, sem sequer pensar.
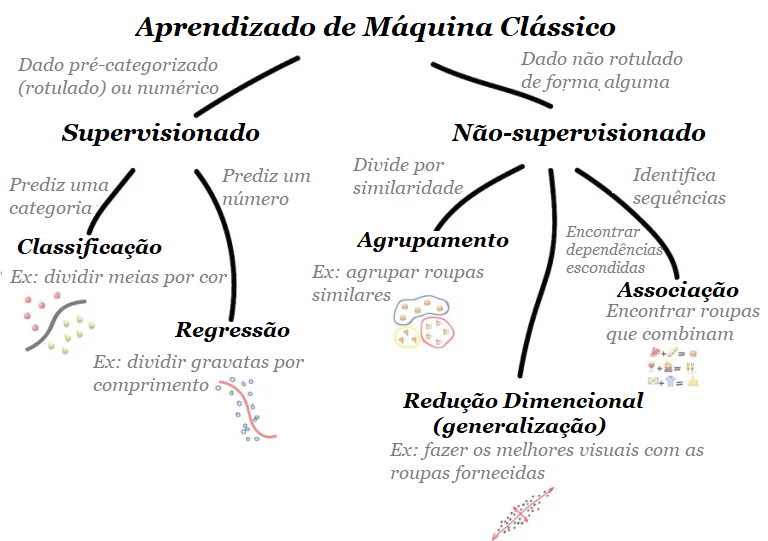
O aprendizado de máquina clássico é frequentemente dividido em duas categorias – Aprendizado Supervisionado e Não Supervisionado.
1.1 – Aprendizado Supervisionado
Nesse primeiro caso, a máquina tem um “supervisor” ou um “professor”, que dá à máquina todas as respostas, como por exemplo para identificar se é um gato ou um cachorro em uma foto. Neste caso, o “professor” já dividiu (rotulou) os dados em gatos e cães e a máquina está usando esses exemplos para aprender.
Aprendizado não supervisionado significa que a máquina é deixada sozinha com uma pilha de fotos de animais e uma tarefa: descobrir quem é quem. Os dados não são rotulados, não há professor e a máquina está tentando encontrar padrões por conta própria. Vamos falar sobre esses métodos abaixo.
Claramente, a máquina aprenderá mais rápido com um professor. Por isso, é mais comum encontrarmos esse caso nas tarefas da vida real.
Existem dois tipos de tarefas: classificação – predição de categoria de um objeto e previsão de regressão – de um ponto específico em um eixo numérico.
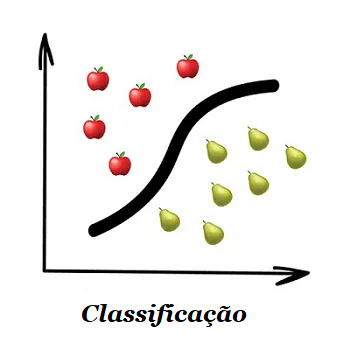
1.1.1 – Classificação
Os algoritmos de classificação dividem os objetos com base em um dos atributos conhecidos de antemão. Separa as meias com base na cor, documentos baseados na linguagem e as músicas por gênero.
Usada nos dias de hoje para:
Filtragem de spam;
Detecção de idioma;
Pesquisa por documentos semelhantes;
Análise de sentimentos;
Reconhecimento de caracteres e números manuscritos;
Aprendizado de máquina é, principalmente, uma tarefa de classificar as coisas. A máquina aqui é como um bebê aprendendo a classificar brinquedos: aqui está um robô, aqui está um carro, aqui está um carro robô etc.
Na classificação, precisa-se sempre de um “professor”. Os dados devem ser rotulados com as características para que a máquina possa atribuir classes com base nelas. Tudo poderia ser classificado – usuários por interesses (como os feeds algorítmicos), artigos baseados em linguagem ou tópicos (isso é importante para os mecanismos de busca), músicas por gênero (playlists do Spotify), até seus e-mails.
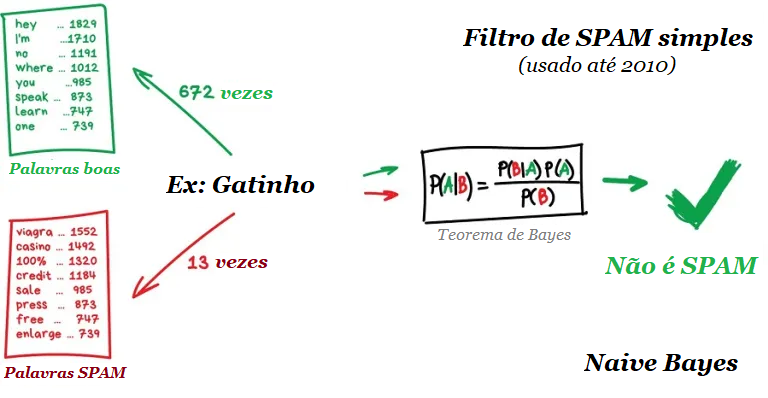
Na filtragem de spam, o algoritmo Naive Bayes é amplamente usado. A máquina conta o número de menções “viagra” no spam e nas mensagens normais, depois multiplica as duas probabilidades usando a equação de Bayes, soma os resultados e Voilá, temos Aprendizado de Máquina.
Entretanto, mais tarde, os spammers aprenderam a lidar com filtros bayesianos adicionando muitas palavras “boas” ao final do e-mail. Ironicamente, o método foi chamado de envenenamento bayesiano.
Naive Bayes entrou para a história como o mais elegante e o primeiro algoritmo realmente útil para essa tarefa. Mas agora outros algoritmos são usados para filtragem de spam.
Outro exemplo prático de classificação, digamos que precisa-se de algum dinheiro a crédito. Como o banco saberá se será pago de volta ou não? Não há como saber com certeza. Mas o banco tem muitos perfis de pessoas das quais recebeu dinheiro antes. Eles têm dados sobre idade, educação, ocupação, salário e – o mais importante – o fato de pagar o dinheiro de volta. Ou não.
Usando esses dados, podemos ensinar a máquina a encontrar padrões e obter a resposta. Entretanto, o banco não pode confiar cegamente na resposta da máquina.
E se houver uma falha no sistema ou ataque hacker?
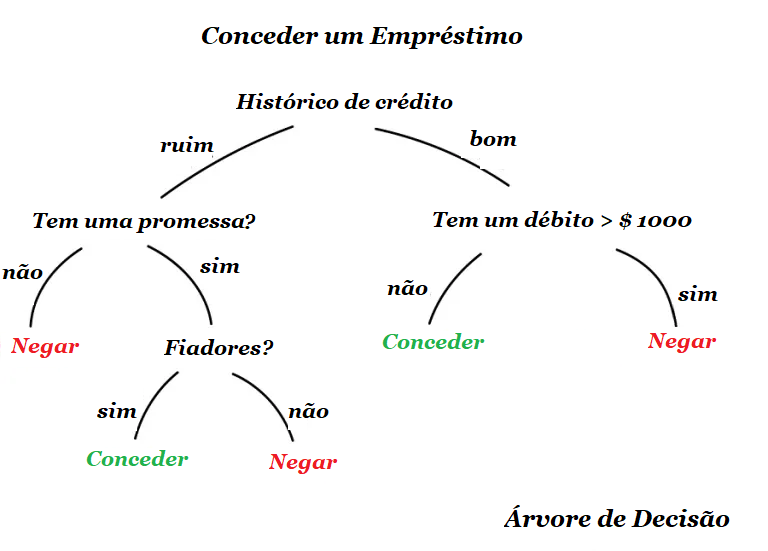
Para lidar com isso, temos as árvores de decisão. Todos os dados são automaticamente divididos em perguntas de sim ou não, que alias poderiam soar um pouco estranhas do ponto de vista humano. Um exemplo de pergunta estranha seria se o credor possui uma renda mensal maior que R$ 1280,50. No entanto, a máquina faz essas perguntas para dividir melhor os dados em cada etapa.
É desse modo que uma árvore de decisão é feita: quanto maior o ramo – mais ampla é a questão. Árvores de decisão são amplamente usadas em esferas de alta responsabilidade: diagnósticos, medicina e finanças.
Árvores de decisão puras raramente são usadas hoje. No entanto, elas frequentemente estabelecem a base para grandes sistemas e seus conjuntos até funcionam melhor que redes neurais.
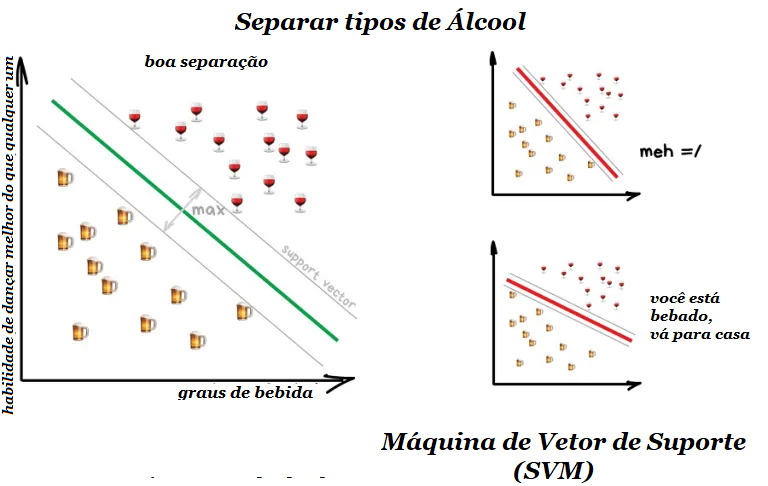
Já o Support Vector Machine (SVM) é o método mais popular de classificação clássica. Foi usado para classificar tudo o que existe: plantas por aparência em fotos, documentos por categorias, etc.
A ideia por trás do SVM é simples – ele tenta desenhar duas linhas entre seus pontos de dados com a maior margem entre eles. Veja a imagem abaixo:
Os mercados de ações utilizam SVM para detectar um eventual comportamento anormal dos comerciantes para encontrar os insiders. Ao ensinar um computador as coisas certas, nós automaticamente ensinamos quais são as coisas que estão erradas.
Atualmente, as redes neurais são mais frequentemente usadas para classificação. Alias, é para isso que elas foram criadas…
A regra geral é quanto mais complexos os dados, mais complexo é o algoritmo. Para textos, números e tabelas, pode-se escolher a abordagem clássica. Os modelos são menores lá, eles aprendem mais rápido e trabalham com mais clareza. Para fotos, vídeos e todas as outras coisas complicadas de Big Data, costuma-se definitivamente optar por redes neurais.
Há apenas cinco anos, você poderia encontrar um classificador de faces construído em SVM. Hoje é mais fácil escolher entre centenas de redes pré-treinadas (modelos). Nada mudou para filtros de spam, no entanto. Muitos ainda são escritos com o SVM e não há uma boa razão para mudar. Até mesmo este site possui detecção de spam baseada em SVM nos comentários ¯_ (ツ) _ / ¯
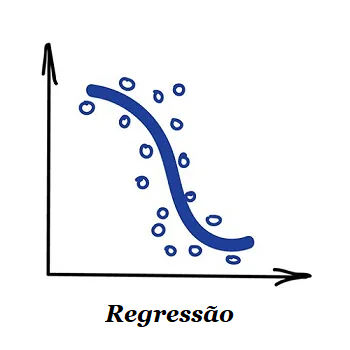
1.1.2 – Regressão
“Desenhe uma linha através desses pontos. Sim, isso é o aprendizado de máquina”.
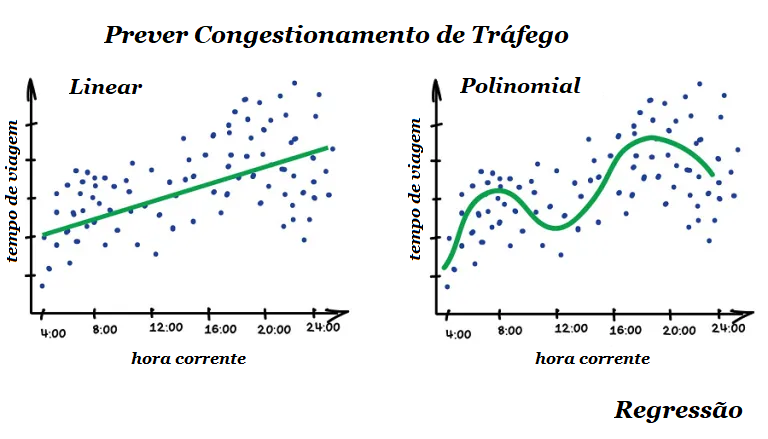
Regressão é basicamente uma classificação em que prevemos um número em vez de uma categoria. Exemplos disso são a previsão do preço de um carro pela sua quilometragem, tráfego por hora do dia, volume de demanda por crescimento da empresa, etc. A regressão é perfeita quando algo depende do tempo.
Todo mundo que trabalha com finanças e análises adora a regressão. Inclusive é embutida no Excel. E é super leve computacionalmente – a máquina simplesmente tenta desenhar uma linha que indica correlação média. Embora, ao contrário de uma pessoa com uma caneta e um quadro branco, a máquina faz isso com precisão matemática, calculando o intervalo médio entre cada ponto.
Quando a linha resultante é reta – é uma regressão linear, quando é curva – polinomial. Esses são os dois tipos principais de regressão. Os outros são mais exóticos. A regressão logística é uma exceção, pois não é uma regressão, mas sim um método de classificação. Fique atento!
Não há problema em trabalhar com regressão e classificação, no entanto muitos classificadores se transformam em regressão após algum ajuste. Podemos não apenas definir a classe do objeto, mas também memorizar o quão próximo ele está. Aí começa a regressão.
1.2 – Aprendizado não supervisionado
O aprendizado não supervisionado foi inventado um pouco mais tarde, nos anos 90. É usado com menos frequência, mas às vezes simplesmente não temos escolha. Os dados rotulados são um luxo. Mas e se alguém quiser criar, digamos, um classificador de ônibus? Deve-se tirar fotos manualmente de milhões de ônibus nas ruas e rotular cada um deles? De jeito nenhum! Isso vai levar uma vida inteira.
Neste caso, ou você recorre ao Mechanical Turk, ou você pode tentar usar o aprendizado não supervisionado.
Geralmente é útil para análise exploratória de dados, mas não como algoritmo principal. Pessoas “especialmente treinadas”, graduadas em “Oxford”, alimentam a máquina com uma tonelada de “lixo” e a observa. Existem alguns clusters? Não. Quaisquer relações visíveis? Não.
1.2.1 – Agrupamento
Usada nos dias de hoje para:
Segmentação de mercado (tipos de clientes, fidelidade);
Mesclar pontos próximos em um mapa;
Compressão de imagem;
Analisar e rotular novos dados;
Detectar um comportamento anormal.
Algoritmos populares: K-means_clustering, Mean-Shift, DBSCAN. Clusterização ou agrupamento (clustering), é uma classificação sem classes predefinidas. É como dividir meias por cor quando você não se lembra de todas as cores que você tem.
O algoritmo de clusterização tenta encontrar objetos semelhantes (por características) e mesclá-los em um grupo (cluster). Aqueles que têm muitas características semelhantes são unidos em uma classe. Com alguns algoritmos, você ainda pode especificar o número exato de clusters que você deseja.
Um excelente exemplo de clusterização são marcadores em mapas da web. Quando você está procurando por todos os restaurantes ao seu redor para escolher a melhor opção para o almoço, o mecanismo de agrupamento agrupa-os em bolhas com um número.
O Apple Photos e o Google Photos usam clusters mais complexos. Eles procuram rostos em fotos para criar álbuns de seus amigos. O aplicativo não sabe quantos amigos você tem e como eles se parecem, mas busca encontrar características faciais comuns. É um agrupamento típico.
Outro problema popular é a compactação de imagens. Ao salvar uma imagem em PNG, você pode definir a paleta, digamos, para 32 cores. Isso significa que o agrupamento encontrará todos os pixels “avermelhados”, calculará o “vermelho médio” e o definirá para todos os pixels vermelhos. Quanto menor o número de cores – menor será o tamanho dos arquivos e menor será o custo!
No entanto, você pode ter problemas com cores do tipo Ciano. Ela é verde ou azul? Aqui entra o algoritmo K-Means.
O K-Means define aleatoriamente 32 pontos de cor na paleta, que são definidos como centroides. Os pontos restantes são marcados como atribuídos ao centroide mais próximo.
Assim, temos tipos de “galáxias” em torno dessas 32 cores. Então, movemos o centroide para o centro de sua galáxia e repetimos o processo até que os centroides parem de se mover.
Tudo pronto! Clusters estão definidos, estáveis e existem exatamente 32 deles. Aqui está uma explicação mais real:
Procurar pelos centroides é conveniente em muitos casos. Entretanto, clusters da vida real nem sempre formam círculos. Vamos imaginar que um geólogo precisa encontrar alguns minerais semelhantes no mapa. Nesse caso, os clusters podem ter uma forma estranha. Além disso, você nem sabe quantos deles esperar. Seriam 10? 100? K-means não se encaixa aqui, mas o DBSCAN pode ser muito útil.
Vamos para um exemplo mais claro do K-means. Digamos que os nossos pontos sejam pessoas na praça da cidade. Encontra-se três pessoas próximas umas das outras e peça para elas darem as mãos. Então, diz-se a elas para começarem a pegar as mãos daqueles vizinhos que eles podem alcançar. E assim por diante, até que ninguém mais possa pegar a mão de ninguém. Esse é o nosso primeiro cluster.
Repita o processo até que todos estejam agrupados. Todas as pessoas que não conseguissem dar as mãos para outras pessoas seriam consideradas anomalias, neste caso.
Assim como a classificação, o agrupamento pode ser usado para detectar anomalias. Um usuário se comporta de forma anormal depois de se inscrever? Deixe a máquina bani-lo temporariamente e crie um ticket para o suporte para verificá-lo. Talvez seja um bot. Nem precisa-se saber o que é “comportamento normal”, apenas faz-se o upload de todas as ações do usuário para o modelo e deixamos a máquina decidir se é um usuário “típico” ou não.
Esta abordagem não funciona tão bem em comparação com a classificação, mas nunca é demais tentar.
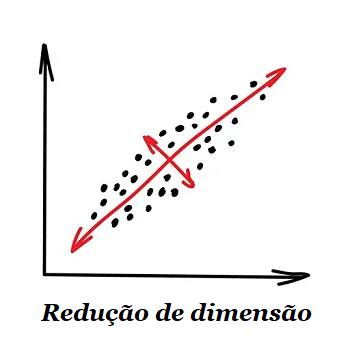
1.2.2 – Redução de Dimensionalidade (Generalização)
“Monta características específicas em mais alto nível”.
Usada nos dias de hoje para:
Criar sistemas de recomendação (★);
Criar belas visualizações;
Modelar tópicos e pesquisa de documentos similares;
Anteriormente, esses métodos eram usados por cientistas de dados experientes, que precisavam encontrar “algo interessante” em enormes quantidades de dados. Quando os gráficos do Excel não ajudaram, eles forçaram as máquinas a fazer a descoberta de padrões. É assim que eles criaram métodos de redução de dimensão.
É sempre mais conveniente que as pessoas usem abstrações, não um monte de recursos fragmentados. Por exemplo, podemos unir todos os cachorros com orelhas triangulares, narizes longos e caudas grandes a uma bela abstração denominada “pastor”. Sim, estamos perdendo algumas informações sobre os pastores específicos, mas a nova abstração é muito mais útil para nomear e explicar propósitos. Como bônus, esses modelos “abstratos” aprendem mais rápido, causam menos “overfit” e usam um número menor de características.
Esses algoritmos se tornaram ferramentas incríveis para Modelagem de Tópicos. Podemos abstrair de palavras específicas até seus significados. É isso que a análise semântica latente (LSA) faz. É baseada em quão frequente você vê a palavra em um tópico específico. Por exemplo, existem mais termos de tecnologia em artigos de tecnologia? Com certeza. Os nomes dos políticos também são encontrados principalmente em notícias políticas, entre outros exemplos.
Sim, podemos fazer clusters de todas as palavras nos artigos, mas perderemos todas as conexões importantes, como, por exemplo, palavras com um mesmo significado em contextos diferentes em documentos diferentes. A LSA lida com isso corretamente e é por isso que é chamada de “semântica latente”.
Então, precisamos conectar as palavras e documentos dentro da uma característica (feature) para manter essas conexões latentes. Ocorre que a decomposição Singular (SVD) resolve essa tarefa, revelando clusters de tópicos úteis a partir de aglomerados de palavras.
Sistemas de recomendação e filtragem colaborativa são outros usos super populares do método de redução de dimensionalidade. Se forem usados para abstrair as classificações do usuário, será um ótimo sistema para recomendar filmes, músicas, jogos e o que se quiser.
É quase impossível entender completamente essa abstração de máquina, mas é possível ver algumas correlações a partir de um olhar mais atento. Algumas delas se correlacionam com a idade do usuário – as crianças que brincam de Minecraft e também assistem mais desenhos animados; outros correlacionam-se com gênero de filme ou hobbies de usuário.
As máquinas obtêm esses conceitos de alto nível mesmo sem entendê-los, com base apenas no conhecimento das classificações dos usuários.
A aprendizagem por regras de associação inclui todos os métodos para analisar carrinhos de compras, automatizar estratégias de marketing e outras tarefas relacionadas a eventos. Quando se tem uma sequência de algo e quer-se encontrar padrões nela – tenta-se associação.
Digamos que um cliente entre um um mercado, pegue um pacote de seis cervejas e vá para o caixa. Deveria colocar amendoins no caminho? Com que frequência as pessoas compram estes dois itens juntos?
Sim, provavelmente funciona para cerveja e amendoim, mas que outras sequências podemos prever? Pode uma pequena mudança no arranjo de mercadorias levar a um aumento significativo nos lucros?
O mesmo vale para o comércio eletrônico. A tarefa é ainda mais interessante – o que o cliente vai comprar da próxima vez?
O aprendizado por regras parece ser o menos elaborado na categoria de aprendizado de máquina. Os métodos clássicos são baseados em uma visão frontal de todos os produtos comprados usando árvores ou conjuntos. Algoritmos só podem procurar por padrões, mas não podem generalizar ou reproduzi-los em novos exemplos.
No mundo real, todo grande varejista constrói sua própria solução proprietária, portanto não há revoluções acontecendo aqui.
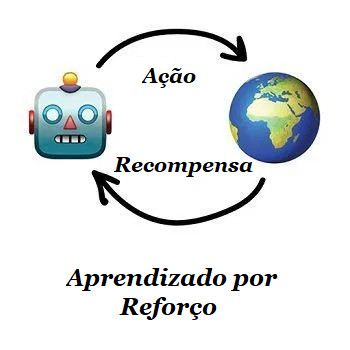
2 – Aprendizagem por Reforço
“Jogue um robô em um labirinto e deixe-o encontrar uma saída”.
Agora chegamos a algo que se parece com inteligência artificial real. Em muitos artigos, o aprendizado por reforço é colocado entre o aprendizado supervisionado e o não supervisionado, mas eles não têm nada em comum!
O aprendizado por reforço é usado nos casos em que seu problema não está relacionado a dados, mas você tem um ambiente virtual ou real para interação, como um mundo de videogame ou uma cidade para carros autônomos.
O conhecimento de todas as regras de trânsito no mundo não ensinará o piloto automático a dirigir nas estradas.
Independentemente da quantidade de dados que coletarmos, ainda não poderemos prever todas as situações possíveis. É por isso que seu objetivo é minimizar o erro, não prever todos os movimentos.
Veja o exemplo abaixo de redes neurais jogando Mário.
Sobreviver dentro de um ambiente é a idéia central do aprendizado por reforço. Através de um sistema de punições e recompensas o robô é ensinado da mesma maneira que uma criança aprende.
Um truque eficaz para construir um modelo de carros autônomos é construir uma cidade virtual e deixar o self-driving-car aprender primeiro todos os seus truques. É exatamente assim que treinamos pilotos automáticos no momento. Crie uma cidade virtual baseada em um mapa real, preencha com pedestres e deixe o carro aprender a matar o menor número possível de pessoas.
Quando o robô está razoavelmente confiante neste “GTA artificial”, é liberado para testar nas ruas reais. Diversão! Pode haver ainda duas abordagens diferentes – com base em modelo e sem modelo.
Baseado em modelo significa que o carro precisa memorizar um mapa ou suas partes. Essa é uma abordagem bastante desatualizada, pois é impossível para o pobre carro autônomo memorizar o planeta inteiro.
No aprendizado sem modelo, o carro não memoriza todos os movimentos, mas tenta generalizar situações e agir racionalmente enquanto obtém uma recompensa máxima.
Isso significa que a máquina mesmo sem se lembrar de todas as combinações, ainda assim, venceu no Go (como aconteceu no xadrez). A cada turno, ela simplesmente escolhia a melhor jogada para cada situação, superando o jogador humano ao final.
Essa abordagem é o conceito central por trás do Q-Learning e seus derivados (SARSA e DQN). ‘Q’ no nome significa “Qualidade”, pois um robô aprende a executar a ação mais “qualitativa” em cada situação e todas as situações são memorizadas como um simples processo markoviano
Essa máquina pode testar bilhões de situações em um ambiente virtual, lembrando quais soluções levaram a uma maior recompensa. Mas como ela pode distinguir situações já vistas anteriormente de uma outra completamente nova?
Se um carro autônomo está em uma estrada e o semáforo fica verde – isso significa que pode ir agora? E se houver uma ambulância correndo por uma rua próxima? A resposta hoje é “ninguém sabe”. Não há resposta fácil. Os pesquisadores estão constantemente pesquisando, mas enquanto isso, apenas encontram soluções alternativas.
Alguns codificariam manualmente todas as situações que os permitiam resolver casos excepcionais, como o Problema de Trolley. Outros se aprofundariam e deixariam as redes neurais fazer o trabalho de descobrir isso. Isso nos levou à evolução do Q-learning, chamado Deep Q-Network (DQN). Embora seja muito bom, não é uma bala de prata.
O aprendizado por reforço para uma pessoa comum pareceria uma inteligência artificial real. Porque faz-se pensar, esta máquina está tomando decisões em situações da vida real! Este tópico está no topo agora, avançando com um ritmo incrível.
Off-Topic. Há alguns anos, algoritmos genéticos eram realmente populares. Trata-se de lançar um monte de robôs em um único ambiente e fazê-los tentar atingir a meta até que eles morram. Depois, escolhemos os melhores, cruzamos-os, modificamos alguns genes e executamos novamente a simulação. Depois de alguns bilhões de anos, teremos uma criatura inteligente. Provavelmente. Evolução no seu melhor.
Os algoritmos genéticos são considerados parte do aprendizado por reforço e possuem a característica mais importante comprovada pela prática de uma década: ninguém dá a mínima para eles.
A humanidade ainda não conseguiu chegar a uma tarefa em que seriam mais eficazes do que outros métodos. Mas eles são ótimos para experiências de estudantes e deixam as pessoas entusiasmadas.
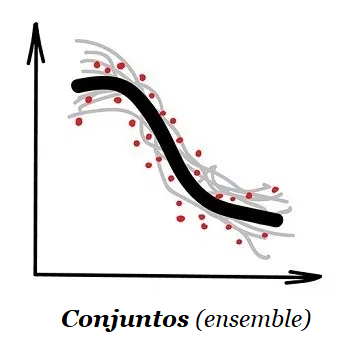
3 – Método Conjuntos (ensemble)
“Um bando de árvores estúpidas aprendendo a corrigir erros umas das outras”
Usado nos dias de hoje para:
Tudo o que se encaixa nas abordagens clássicas de algoritmos (mas funciona melhor);
Finalmente chegamos aos métodos considerados mais vanguarda. Ensemble e Redes Neurais são os dois principais competidores na disputa para o caminho para a singularidade. Hoje eles estão produzindo os resultados mais precisos e são amplamente utilizados em produção.
Apesar de toda a eficácia, a idéia por trás disso é excessivamente simples. Pegando-se um monte de algoritmos ineficientes e forçando-os a corrigir os erros um dos outros, a qualidade geral de um sistema será maior do que os melhores algoritmos individuais.
Obter-se-á resultados ainda melhores com o uso dos algoritmos mais instáveis que estão prevendo resultados completamente diferentes com pouco ruído nos dados de entrada. A Regressão e Árvores de Decisão, por exemplo, são tão sensíveis que até mesmo um único dado fora do comum (outlier) nos dados de entrada pode levar os modelos a enlouquecerem.
Pode-se usar qualquer algoritmo que conhecemos para criar um Ensenble, que na tradução é “conjunto”. Basta jogar um monte de classificadores, apimentar com regressão e não se esqueça de medir a precisão. Por outro lado evita-se um Bayes ou kNN aqui. Embora “burros”, eles são realmente estáveis.
Em vez disso, existem três métodos testados em campo para criar Ensembles.
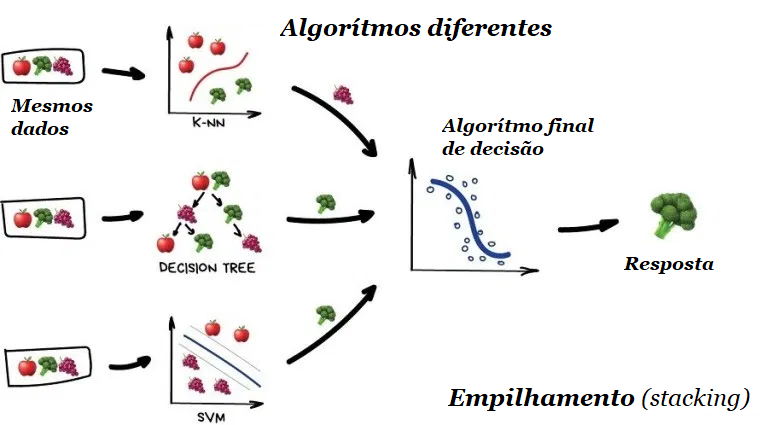
3.1 – Empilhamento (stacking)
A saída de vários modelos paralelos é passada como entrada para o último que toma uma decisão final. É como aquela garota que pergunta para as amigas se deve se encontrar com alguém, antes de tomar uma decisão final. Não somos tão diferentes desses algoritmos não é mesmo?
Ressalto aqui a palavra “diferente”. Misturar os mesmos algoritmos nos mesmos dados não faria sentido. A escolha dos algoritmos é totalmente de quem está resolvendo o problema. No entanto, para o modelo final de tomada de decisão, a regressão geralmente é uma boa escolha. Na prática, o Stacking tem sido menos popular porque os dois próximos métodos estão fornecendo melhor precisão.
3.2 – Ensacamento (bagging)
Também conhecido como Bootstrap AGGregatING. É um método que usa os mesmos algoritmos, mas treina-os com diferentes subconjuntos de dados originais e no final usa apenas os resultados médios. Dados em subconjuntos aleatórios podem se repetir. Por exemplo, de um conjunto como “1-2-3”, podemos obter subconjuntos como “2-2-3”, “1-2-2”, “3-1-2” e assim por diante. Usamos esses novos conjuntos de dados para ensinar o mesmo algoritmo várias vezes e, em seguida, prever a resposta final por meio da votação majoritária simples.
O exemplo mais famoso de Bagging é o algoritmo Random Forest que é simplesmente resultado de várias árvores de decisão, conforme ilustrado acima.
Quando se abre o aplicativo de câmera do telefone e o vê desenhando caixas em volta do rosto das pessoas – provavelmente é o resultado do trabalho do Random Forest. As redes neurais seriam muito lentas para serem executadas em tempo real, por isso, o método de Bagging, neste caso, é o ideal.
Em algumas tarefas, a capacidade do Random Forest de executar em paralelo é mais importante do que uma pequena perda de precisão no reforço, por exemplo. Especialmente no processamento em tempo real. Quando falamos de Machine Learning, sempre temos um trade-off.
3.3 – Impulsionamento (boosting)
No método de Boosting, os algoritmos são treinados um a um sequencialmente. Cada algoritmo subsequente presta mais atenção aos pontos de dados que foram imprevisíveis pelo anterior. Esse processo ocorre até o resultado ser satisfatório.
Do mesmo modo que o método Bagging, usamos subconjuntos de nossos dados, mas desta vez eles não são gerados aleatoriamente. Agora, em cada subamostra, coletamos uma parte dos dados que o algoritmo anterior falhou ao processar
Assim, o novo algoritmo aprende a corrigir os erros do anterior.
A principal vantagem aqui é uma precisão de classificação muito alta. Os contras já foram destacados – não são processados de forma paralela, o que pode torná-lo não tão rápido. Entretanto, ainda assim, é mais rápido que as redes neurais.
Na verdade, é como uma corrida entre um caminhão de lixo e um carro de corrida. O caminhão pode fazer mais, mas se você quiser ir mais rápido, pegue um automóvel.
Se você quiser um exemplo real do Método de Boosting é só abrir o Facebook ou o Google e começar a digitar uma consulta de pesquisa. O resultado dessa pesquisa é trazido pelo Método Ensemble utilizando boosting.
4 – Redes Neurais e Aprendizagem Profunda
“Temos uma rede de mil camadas, dezenas de placas de vídeo, mas ainda não sabemos onde usá-la. Vamos gerar fotos de gatos!”.
Usado nos dias de hoje para:
Substituição dos algoritmos de aprendizagem de máquina tradicionais;
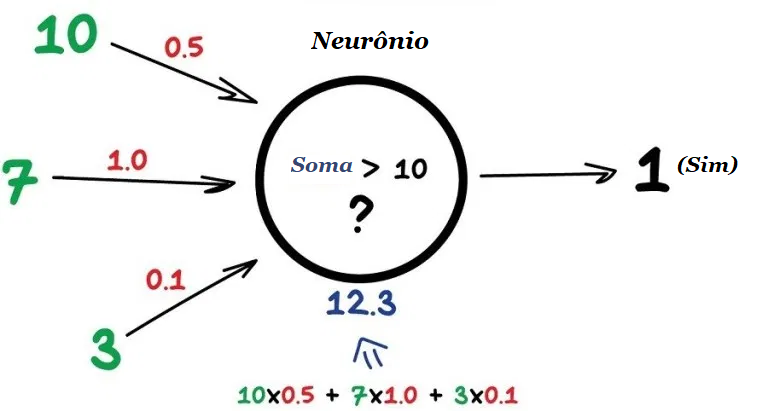
Qualquer rede neural artificial é basicamente uma coleção de neurônios artificiais e conexões entre eles. O neurônio é uma função com várias entradas e uma saída. Sua tarefa é pegar todos os números de sua entrada, executar uma função neles e enviar o resultado para a saída.
Aqui está um exemplo de um neurônio simples, mas útil na vida real: some todos os números das entradas e se essa soma for maior que N – dê “1” como resultado. Caso contrário – “zero”.
As conexões são como canais entre os neurônios. Eles conectam as saídas de um neurônio às entradas de outro, para que possam enviar dígitos um para o outro. Cada conexão possui apenas um parâmetro – peso. É como uma força de conexão para um sinal. Quando o número 10 passa por uma conexão com um peso 0,5, ele se transforma em 5.
Esses pesos dizem ao neurônio para responder mais a uma entrada e menos a outra. Os pesos são ajustados durante o treinamento – é assim que a rede aprende. Basicamente, é só isso.
Para impedir que a rede caia na anarquia, os neurônios são ligados por camadas, não aleatoriamente. Dentro de uma camada, os neurônios não estão conectados, mas estão conectados aos neurônios da camada “seguinte” e da camada “anterior”. Os dados na rede vão estritamente em uma direção – das entradas da primeira camada às saídas da última.
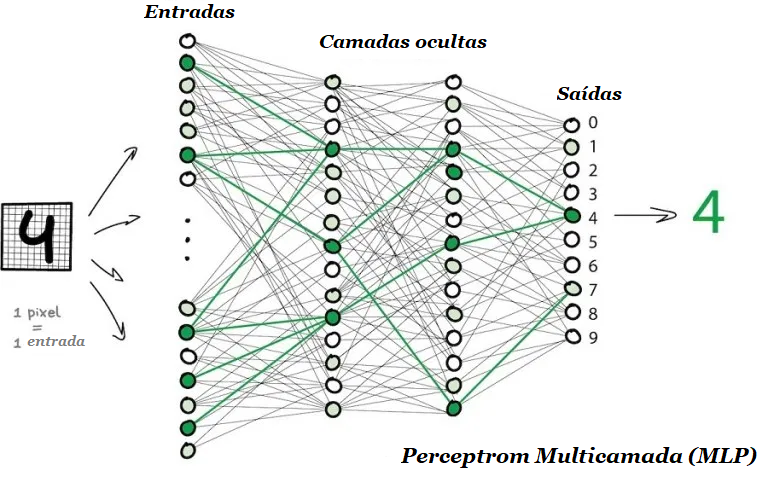
Se você lançar um número suficiente de camadas e colocar os pesos corretamente, obterá o seguinte: aplicando à entrada, digamos, a imagem do dígito manuscrito 4, pixels pretos ativam os neurônios associados, eles ativam as próximas camadas e assim por diante, até que finalmente acenda a saída encarregada dos quatro. O resultado é alcançado.
Uma rede que possui várias camadas que têm conexões entre todos os neurônios é chamada de perceptron (MLP), conforme imagem acima, e é considerada a arquitetura mais simples para um iniciante, embora não seja vista em produção.
Ao fazer a programação da vida real, ninguém escreve neurônios e conexões. Em vez disso, tudo é representado como matrizes e calculado com base na multiplicação de matrizes para melhor desempenho.
Este vídeo sobre isso, e sua sequência abaixo, descreve todo o processo de uma maneira facilmente digerível, usando o exemplo do reconhecimento de dígitos escritos à mão. Assista-o se você quiser entender melhor.
Depois que construímos uma rede, nossa tarefa é atribuir maneiras apropriadas para que os neurônios reajam corretamente aos sinais recebidos. Agora é a hora de lembrar que temos dados que são amostras de ‘entradas’ e ‘saídas’ apropriadas. Mostraremos à nossa rede um desenho do mesmo dígito 4 e informaremos ‘adapte seus pesos para que, sempre que você vir essa entrada, sua saída emita 4’. Para começar, todos os pesos são atribuídos aleatoriamente. Depois que mostramos um dígito, ele emite uma resposta aleatória porque os pesos ainda não estão corretos e comparamos o quanto esse resultado difere do correto.
Então começa-se a atravessar a rede de saída para entrada e dizemos a todos os neurônios: “ei, você ativou aqui, mas você fez um péssimo trabalho, vamos dar menos atenção a essa e mais a essa outra, ok?”
Depois de centenas de milhares de ciclos desse tipo de ‘inferir / punir’, há uma esperança de que os pesos sejam corrigidos e ajam como pretendido. O nome científico dessa abordagem é Backpropagation. O engraçado foi que levaram vinte anos para criar esse método. Esse segundo vídeo descreve esse processo com maior profundidade, mas ainda é muito acessível.
Uma rede neural bem treinada pode falsificar o trabalho de qualquer um dos algoritmos descritos neste capítulo (e freqüentemente funciona com mais precisão). Essa universalidade é o que a tornou amplamente popular.
Finalmente, temos uma arquitetura do cérebro humano, eles disseram que precisamos montar muitas camadas e ensiná-las sobre todos os dados possíveis que esperavam. Então, o primeiro inverno da IA começou, depois se derreteu e outra onda de decepção ocorreu.
Descobriu-se que as redes com um grande número de camadas exigiam um poder de computação inimaginável na época. Atualmente, qualquer PC com placas de vídeo Geforce supera os datacenters da época. Portanto, as pessoas não tinham nenhuma esperança de adquirir poder computacional como os que hoje temoa acesso e as redes neurais eram uma chatice enorme.
E então, dez anos atrás, o Deep Learning floresceu!
Há uma boa linha do tempo de aprendizado de máquina descrevendo a montanha-russa de esperanças e ondas de pessimismo. Em 2012, as redes neurais convolucionais conquistaram uma vitória esmagadora na competição ImageNet que fez o mundo se lembrar repentinamente dos métodos de Deep Learning descritos nos anos 90 e que agora se tornam viáveis com nossas placas de vídeo!
As diferenças do Deep Learning das redes neurais clássicas estavam em novos métodos de treinamento que podiam lidar com redes maiores. Atualmente, apenas a teoria tentaria dividir qual aprendizado considerar profundo e não tão profundo. Nós, como profissionais, usamos bibliotecas ‘profundas’ populares como Keras, TensorFlow e PyTorch, mesmo quando construímos uma mini-rede com cinco camadas. Só porque é mais adequado do que todas as ferramentas que vieram antes. Nós apenas as chamamos de redes neurais. Existe um artigo excelente chamado Neural Network Zoo, onde quase todos os tipos de redes neurais são explicadas brevemente.