O objetivo deste artigo é apresentar resumidamente uma introdução a alguns dos componentes mais importantes da inteligência artificial, sob o ponto de vista técnico, porém voltado a lideres e gestores negócios e iniciantes no tema, considerando: o aprendizado de máquina (machine learning), a aprendizagem profunda (deep learning) e a aprendizagem por reforço (reinforcement learning).
Uma visão geral sobre o tema pode ser visualizada com este primeiro diagrama que mostra a Relação entre a Inteligência Artificial, Aprendizado de Máquina e Aprendizagem Profunda:

Arthur Samuel descreveu-o em 1959 como: “o campo de estudo que dá aos computadores a capacidade de aprender sem serem explicitamente programados”. Esta é uma definição mais antiga e informal.
Tom Mitchell fornece uma definição mais moderna: “Diz-se que um programa de computador aprende com a experiência E em relação a alguma classe de tarefas T e medida de desempenho P, se seu desempenho em tarefas em T, medido por P, melhora com a experiência E.”
Esse diagrama simplificado apresenta a diferença básica entre a Programação Clássica de computadores versus a Aprendizagem de Máquina, como segue:
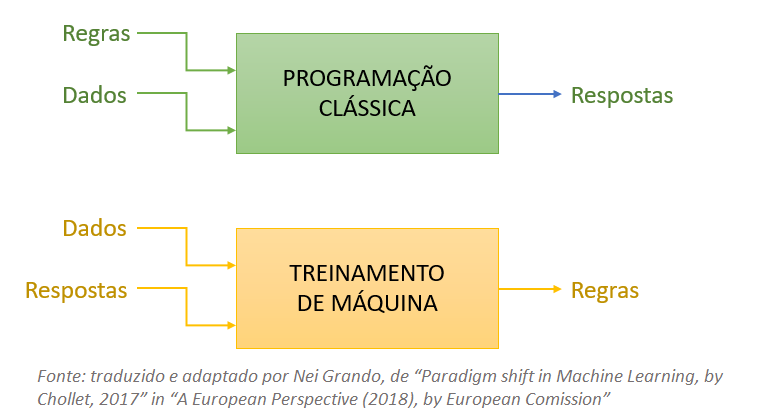
A seguir serão apresentados alguns diagramas simplificados (em inglês), obtidos do post “Machine Learning for Everyone“, com uma breve explicação (traduzida para o português).
Vale lembrar que o aprendizado de máquina depende essencialmente de três elementos: 1) Dados – com quantidade maior possível e qualidade o melhor de dados possível, relacionados ao problema que se deseja resolver; 2) Algoritmos – com o algoritmo ou conjunto deles, apropriado(s) para resolver o problema desejado; e 3) Parâmetros – usados no ajuste do tratamento dos dados.

Estes três elementos servirão durante o desenvolvimento para gerar um determinado Modelo de aprendizado que será utilizado para obter soluções a partir de novos dados em testes ou produção. Em alguns casos podem ser necessários ajustes nos parâmetros, mais e/ou melhores dados, ou até mesmo a troca do algoritmo por outro obtenha melhor precisão de resultados.
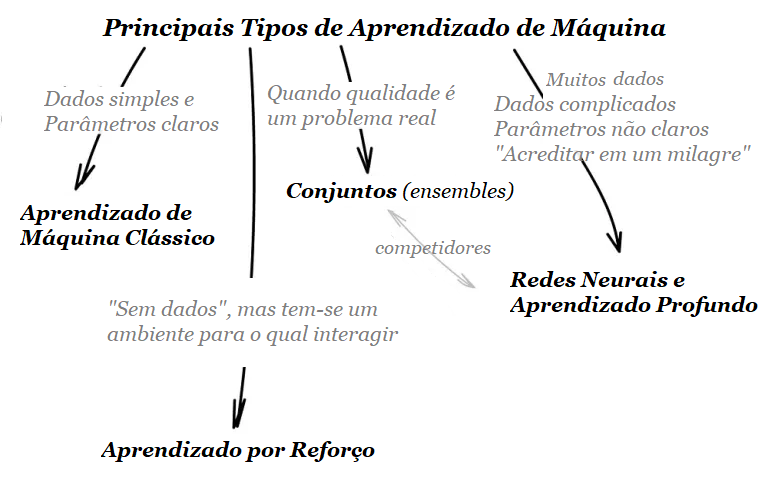
Os principais tipos de aprendizagem de máquina
É importante destacar que não há uma única maneira de resolver um problema no mundo da aprendizagem de máquinas, pois existem vários algoritmos adequados ao problema, assim precisa-se escolher qual deles se encaixa melhor. Quase tudo pode ser resolvido com uma rede neural, por exemplo, mas nem sempre é a melhor solução, principalmente devido ao custo computacional.
Seguem quatro direções principais no aprendizado de máquina.
1 – Aprendizado de máquina clássico
Os primeiros métodos vieram da estatística pura nos anos 50. Eles resolviam tarefas matemáticas formais – procurando padrões em números, avaliando a proximidade dos pontos de dados e calculando as direções dos vetores.
Hoje em dia, metade da Internet funciona baseada nestes algoritmos. Quando se vê uma lista de artigos para “ler em seguida” ou o banco bloqueia o cartão de alguém em um posto de gasolina aleatório no meio do nada, provavelmente é o trabalho de um algoritmo de machine learning.
Empresas de tecnologia são grandes fãs de redes neurais, obviamente. Para elas, uma precisão de 2% é uma receita adicional de 2 bilhões. Mas quando você é pequeno, não faz sentido tanto esforço.
Há histórias de equipes gastando um ano em um novo algoritmo de recomendação para o site de comércio eletrônico, antes de descobrir que 99% do tráfego vem de mecanismos de pesquisa. Seus algoritmos eram inúteis. A maioria dos usuários nem abriu a página principal.
Apesar da popularidade, as abordagens clássicas são tão naturais que você poderia facilmente explicá-las a uma criança. Elas são como aritmética básica, as usamos todos os dias, sem sequer pensar.
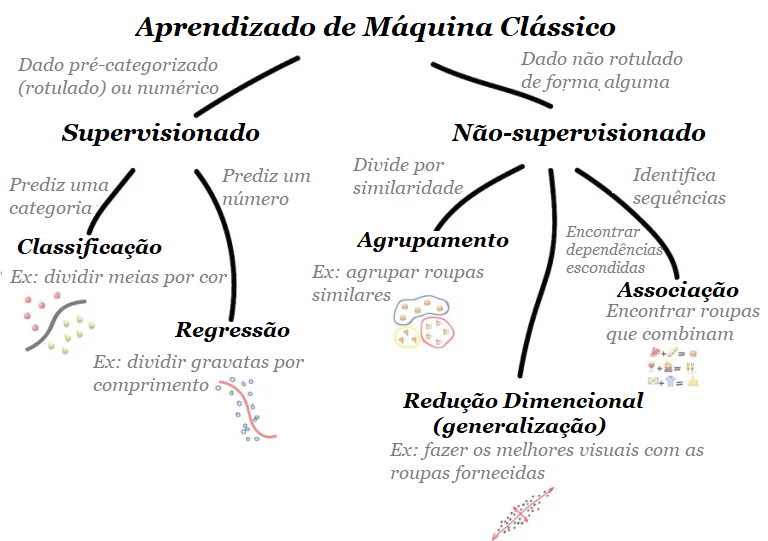
O aprendizado de máquina clássico é frequentemente dividido em duas categorias – Aprendizado Supervisionado e Não Supervisionado.
1.1 – Aprendizado Supervisionado
Nesse primeiro caso, a máquina tem um “supervisor” ou um “professor”, que dá à máquina todas as respostas, como por exemplo para identificar se é um gato ou um cachorro em uma foto. Neste caso, o “professor” já dividiu (rotulou) os dados em gatos e cães e a máquina está usando esses exemplos para aprender.
Aprendizado não supervisionado significa que a máquina é deixada sozinha com uma pilha de fotos de animais e uma tarefa: descobrir quem é quem. Os dados não são rotulados, não há professor e a máquina está tentando encontrar padrões por conta própria. Vamos falar sobre esses métodos abaixo.
Claramente, a máquina aprenderá mais rápido com um professor. Por isso, é mais comum encontrarmos esse caso nas tarefas da vida real.
Existem dois tipos de tarefas: classificação – predição de categoria de um objeto e previsão de regressão – de um ponto específico em um eixo numérico.
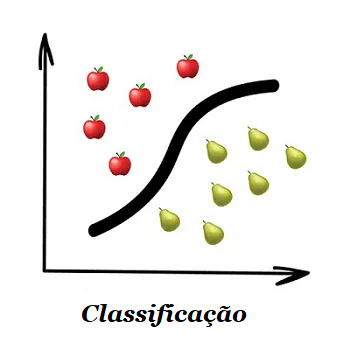
1.1.1 – Classificação
Os algoritmos de classificação dividem os objetos com base em um dos atributos conhecidos de antemão. Separa as meias com base na cor, documentos baseados na linguagem e as músicas por gênero.
Usada nos dias de hoje para:
- Filtragem de spam;
- Detecção de idioma;
- Pesquisa por documentos semelhantes;
- Análise de sentimentos;
- Reconhecimento de caracteres e números manuscritos;
- Detecção de fraude.
Algoritmos populares: Naive Bayes, Decision Tree, Logistic Regression, K-Nearest Neighbours, Support Vector Machine.
Aprendizado de máquina é, principalmente, uma tarefa de classificar as coisas. A máquina aqui é como um bebê aprendendo a classificar brinquedos: aqui está um robô, aqui está um carro, aqui está um carro robô etc.
Na classificação, precisa-se sempre de um “professor”. Os dados devem ser rotulados com as características para que a máquina possa atribuir classes com base nelas. Tudo poderia ser classificado – usuários por interesses (como os feeds algorítmicos), artigos baseados em linguagem ou tópicos (isso é importante para os mecanismos de busca), músicas por gênero (playlists do Spotify), até seus e-mails.
Na filtragem de spam, o algoritmo Naive Bayes é amplamente usado. A máquina conta o número de menções “viagra” no spam e nas mensagens normais, depois multiplica as duas probabilidades usando a equação de Bayes, soma os resultados e Voilá, temos Aprendizado de Máquina.
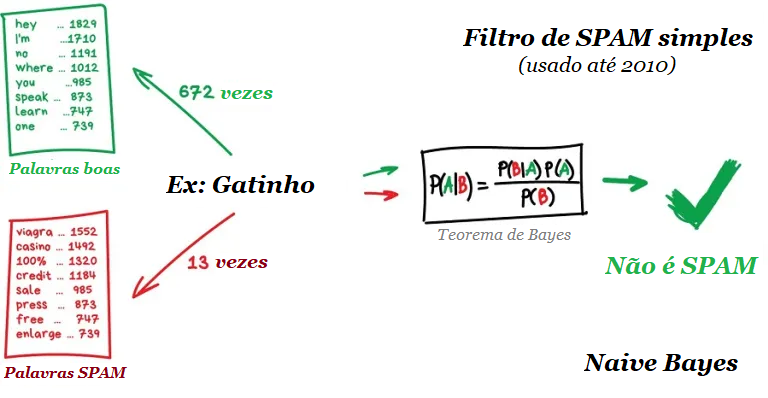
Entretanto, mais tarde, os spammers aprenderam a lidar com filtros bayesianos adicionando muitas palavras “boas” ao final do e-mail. Ironicamente, o método foi chamado de envenenamento bayesiano.
Naive Bayes entrou para a história como o mais elegante e o primeiro algoritmo realmente útil para essa tarefa. Mas agora outros algoritmos são usados para filtragem de spam.
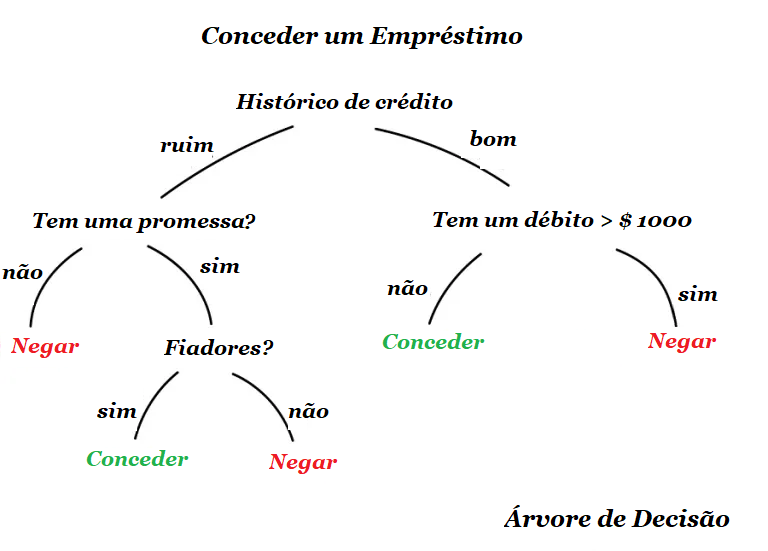
Outro exemplo prático de classificação, digamos que precisa-se de algum dinheiro a crédito. Como o banco saberá se será pago de volta ou não? Não há como saber com certeza. Mas o banco tem muitos perfis de pessoas das quais recebeu dinheiro antes. Eles têm dados sobre idade, educação, ocupação, salário e – o mais importante – o fato de pagar o dinheiro de volta. Ou não.
Usando esses dados, podemos ensinar a máquina a encontrar padrões e obter a resposta. Entretanto, o banco não pode confiar cegamente na resposta da máquina.
E se houver uma falha no sistema ou ataque hacker?
Para lidar com isso, temos as árvores de decisão. Todos os dados são automaticamente divididos em perguntas de sim ou não, que alias poderiam soar um pouco estranhas do ponto de vista humano.
Um exemplo de pergunta estranha seria se o credor possui uma renda mensal maior que R$ 1280,50. No entanto, a máquina faz essas perguntas para dividir melhor os dados em cada etapa.
É desse modo que uma árvore de decisão é feita: quanto maior o ramo – mais ampla é a questão. Árvores de decisão são amplamente usadas em esferas de alta responsabilidade: diagnósticos, medicina e finanças.
Árvores de decisão puras raramente são usadas hoje. No entanto, elas frequentemente estabelecem a base para grandes sistemas e seus conjuntos até funcionam melhor que redes neurais.
Já o Support Vector Machine (SVM) é o método mais popular de classificação clássica. Foi usado para classificar tudo o que existe: plantas por aparência em fotos, documentos por categorias, etc.
A ideia por trás do SVM é simples – ele tenta desenhar duas linhas entre seus pontos de dados com a maior margem entre eles. Veja a imagem abaixo:
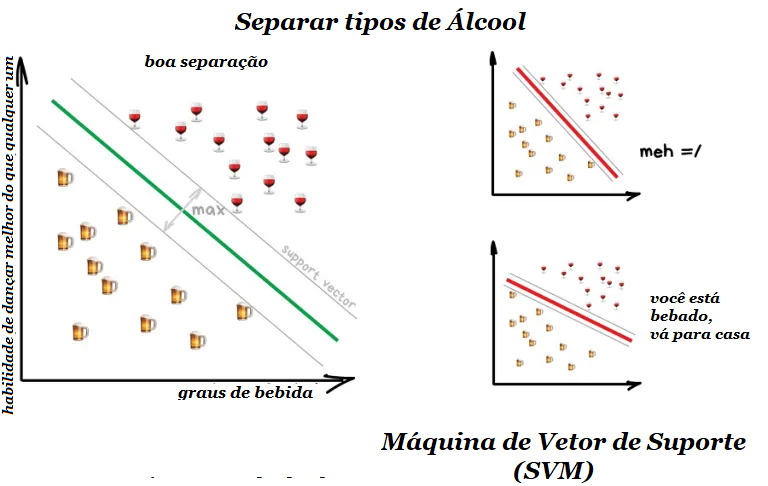
Os mercados de ações utilizam SVM para detectar um eventual comportamento anormal dos comerciantes para encontrar os insiders. Ao ensinar um computador as coisas certas, nós automaticamente ensinamos quais são as coisas que estão erradas.
Atualmente, as redes neurais são mais frequentemente usadas para classificação.
Alias, é para isso que elas foram criadas…
A regra geral é quanto mais complexos os dados, mais complexo é o algoritmo. Para textos, números e tabelas, pode-se escolher a abordagem clássica. Os modelos são menores lá, eles aprendem mais rápido e trabalham com mais clareza. Para fotos, vídeos e todas as outras coisas complicadas de Big Data, costuma-se definitivamente optar por redes neurais.
Há apenas cinco anos, você poderia encontrar um classificador de faces construído em SVM. Hoje é mais fácil escolher entre centenas de redes pré-treinadas (modelos). Nada mudou para filtros de spam, no entanto. Muitos ainda são escritos com o SVM e não há uma boa razão para mudar.
Até mesmo este site possui detecção de spam baseada em SVM nos comentários ¯_ (ツ) _ / ¯
1.1.2 – Regressão
“Desenhe uma linha através desses pontos. Sim, isso é o aprendizado de máquina”.
Usada nos dias de hoje para:
- Previsões do preço das ações;
- Análise de demanda e volume de vendas;
- Diagnóstico médico;
- Quaisquer correlações numéricas.
Algoritmos populares: Regressão Linear e Regressão Polinomial.
Regressão é basicamente uma classificação em que prevemos um número em vez de uma categoria. Exemplos disso são a previsão do preço de um carro pela sua quilometragem, tráfego por hora do dia, volume de demanda por crescimento da empresa, etc. A regressão é perfeita quando algo depende do tempo.
Todo mundo que trabalha com finanças e análises adora a regressão. Inclusive é embutida no Excel. E é super leve computacionalmente – a máquina simplesmente tenta desenhar uma linha que indica correlação média. Embora, ao contrário de uma pessoa com uma caneta e um quadro branco, a máquina faz isso com precisão matemática, calculando o intervalo médio entre cada ponto.
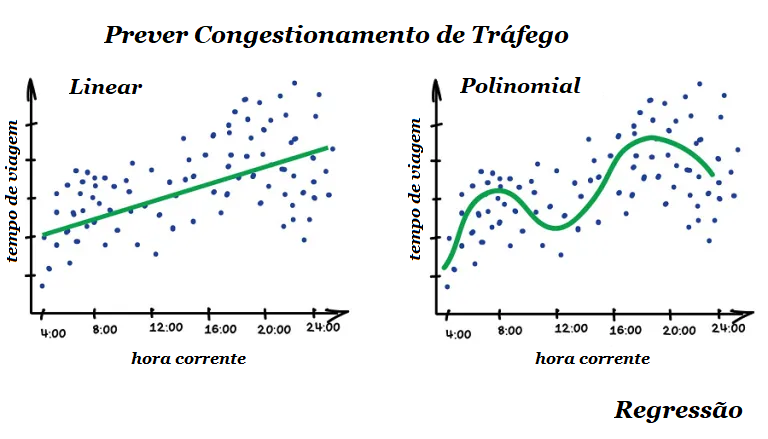
Quando a linha resultante é reta – é uma regressão linear, quando é curva – polinomial. Esses são os dois tipos principais de regressão. Os outros são mais exóticos. A regressão logística é uma exceção, pois não é uma regressão, mas sim um método de classificação. Fique atento!
Não há problema em trabalhar com regressão e classificação, no entanto muitos classificadores se transformam em regressão após algum ajuste. Podemos não apenas definir a classe do objeto, mas também memorizar o quão próximo ele está. Aí começa a regressão.
1.2 – Aprendizado não supervisionado
O aprendizado não supervisionado foi inventado um pouco mais tarde, nos anos 90. É usado com menos frequência, mas às vezes simplesmente não temos escolha.
Os dados rotulados são um luxo. Mas e se alguém quiser criar, digamos, um classificador de ônibus? Deve-se tirar fotos manualmente de milhões de ônibus nas ruas e rotular cada um deles? De jeito nenhum! Isso vai levar uma vida inteira.
Neste caso, ou você recorre ao Mechanical Turk, ou você pode tentar usar o aprendizado não supervisionado.
Geralmente é útil para análise exploratória de dados, mas não como algoritmo principal. Pessoas “especialmente treinadas”, graduadas em “Oxford”, alimentam a máquina com uma tonelada de “lixo” e a observa. Existem alguns clusters? Não. Quaisquer relações visíveis? Não.
1.2.1 – Agrupamento

Usada nos dias de hoje para:
- Segmentação de mercado (tipos de clientes, fidelidade);
- Mesclar pontos próximos em um mapa;
- Compressão de imagem;
- Analisar e rotular novos dados;
- Detectar um comportamento anormal.
Algoritmos populares: K-means_clustering, Mean-Shift, DBSCAN.
Clusterização ou agrupamento (clustering), é uma classificação sem classes predefinidas. É como dividir meias por cor quando você não se lembra de todas as cores que você tem.
O algoritmo de clusterização tenta encontrar objetos semelhantes (por características) e mesclá-los em um grupo (cluster). Aqueles que têm muitas características semelhantes são unidos em uma classe. Com alguns algoritmos, você ainda pode especificar o número exato de clusters que você deseja.
Um excelente exemplo de clusterização são marcadores em mapas da web. Quando você está procurando por todos os restaurantes ao seu redor para escolher a melhor opção para o almoço, o mecanismo de agrupamento agrupa-os em bolhas com um número.
O Apple Photos e o Google Photos usam clusters mais complexos. Eles procuram rostos em fotos para criar álbuns de seus amigos. O aplicativo não sabe quantos amigos você tem e como eles se parecem, mas busca encontrar características faciais comuns. É um agrupamento típico.
Outro problema popular é a compactação de imagens. Ao salvar uma imagem em PNG, você pode definir a paleta, digamos, para 32 cores. Isso significa que o agrupamento encontrará todos os pixels “avermelhados”, calculará o “vermelho médio” e o definirá para todos os pixels vermelhos. Quanto menor o número de cores – menor será o tamanho dos arquivos e menor será o custo!
No entanto, você pode ter problemas com cores do tipo Ciano. Ela é verde ou azul? Aqui entra o algoritmo K-Means.
O K-Means define aleatoriamente 32 pontos de cor na paleta, que são definidos como centroides. Os pontos restantes são marcados como atribuídos ao centroide mais próximo.
Assim, temos tipos de “galáxias” em torno dessas 32 cores. Então, movemos o centroide para o centro de sua galáxia e repetimos o processo até que os centroides parem de se mover.
Tudo pronto! Clusters estão definidos, estáveis e existem exatamente 32 deles. Aqui está uma explicação mais real:

Procurar pelos centroides é conveniente em muitos casos. Entretanto, clusters da vida real nem sempre formam círculos. Vamos imaginar que um geólogo precisa encontrar alguns minerais semelhantes no mapa. Nesse caso, os clusters podem ter uma forma estranha. Além disso, você nem sabe quantos deles esperar. Seriam 10? 100? K-means não se encaixa aqui, mas o DBSCAN pode ser muito útil.
Vamos para um exemplo mais claro do K-means. Digamos que os nossos pontos sejam pessoas na praça da cidade. Encontra-se três pessoas próximas umas das outras e peça para elas darem as mãos. Então, diz-se a elas para começarem a pegar as mãos daqueles vizinhos que eles podem alcançar. E assim por diante, até que ninguém mais possa pegar a mão de ninguém. Esse é o nosso primeiro cluster.
Repita o processo até que todos estejam agrupados. Todas as pessoas que não conseguissem dar as mãos para outras pessoas seriam consideradas anomalias, neste caso.
Assim como a classificação, o agrupamento pode ser usado para detectar anomalias.
Um usuário se comporta de forma anormal depois de se inscrever? Deixe a máquina bani-lo temporariamente e crie um ticket para o suporte para verificá-lo. Talvez seja um bot. Nem precisa-se saber o que é “comportamento normal”, apenas faz-se o upload de todas as ações do usuário para o modelo e deixamos a máquina decidir se é um usuário “típico” ou não.
Esta abordagem não funciona tão bem em comparação com a classificação, mas nunca é demais tentar.
1.2.2 – Redução de Dimensionalidade (Generalização)
“Monta características específicas em mais alto nível”.
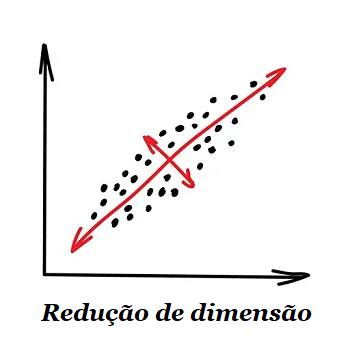
Usada nos dias de hoje para:
- Criar sistemas de recomendação (★);
- Criar belas visualizações;
- Modelar tópicos e pesquisa de documentos similares;
- Análise de imagens falsas;
- Gerenciamento de riscos.
Algoritmos populares: Principal Component Analysis (PCA), Singular Value Decomposition(SVD), Latent Dirichlet allocation (LDA), Latent Semantic Analysis (LSA, pLSA, GLSA), t-SNE (para visualização).
Anteriormente, esses métodos eram usados por cientistas de dados experientes, que precisavam encontrar “algo interessante” em enormes quantidades de dados. Quando os gráficos do Excel não ajudaram, eles forçaram as máquinas a fazer a descoberta de padrões. É assim que eles criaram métodos de redução de dimensão.
É sempre mais conveniente que as pessoas usem abstrações, não um monte de recursos fragmentados. Por exemplo, podemos unir todos os cachorros com orelhas triangulares, narizes longos e caudas grandes a uma bela abstração denominada “pastor”. Sim, estamos perdendo algumas informações sobre os pastores específicos, mas a nova abstração é muito mais útil para nomear e explicar propósitos. Como bônus, esses modelos “abstratos” aprendem mais rápido, causam menos “overfit” e usam um número menor de características.
Esses algoritmos se tornaram ferramentas incríveis para Modelagem de Tópicos. Podemos abstrair de palavras específicas até seus significados. É isso que a análise semântica latente (LSA) faz. É baseada em quão frequente você vê a palavra em um tópico específico. Por exemplo, existem mais termos de tecnologia em artigos de tecnologia? Com certeza. Os nomes dos políticos também são encontrados principalmente em notícias políticas, entre outros exemplos.
Sim, podemos fazer clusters de todas as palavras nos artigos, mas perderemos todas as conexões importantes, como, por exemplo, palavras com um mesmo significado em contextos diferentes em documentos diferentes. A LSA lida com isso corretamente e é por isso que é chamada de “semântica latente”.
Então, precisamos conectar as palavras e documentos dentro da uma característica (feature) para manter essas conexões latentes. Ocorre que a decomposição Singular (SVD) resolve essa tarefa, revelando clusters de tópicos úteis a partir de aglomerados de palavras.

Sistemas de recomendação e filtragem colaborativa são outros usos super populares do método de redução de dimensionalidade. Se forem usados para abstrair as classificações do usuário, será um ótimo sistema para recomendar filmes, músicas, jogos e o que se quiser.
É quase impossível entender completamente essa abstração de máquina, mas é possível ver algumas correlações a partir de um olhar mais atento. Algumas delas se correlacionam com a idade do usuário – as crianças que brincam de Minecraft e também assistem mais desenhos animados; outros correlacionam-se com gênero de filme ou hobbies de usuário.
As máquinas obtêm esses conceitos de alto nível mesmo sem entendê-los, com base apenas no conhecimento das classificações dos usuários.
1.2.3 – Regras de Associação
“Procure padrões na ordem das escolhas”.

Usada nos dias de hoje para:
- Para prever vendas e descontos;
- Para analisar mercadorias compradas em conjunto;
- Para colocar os produtos nas prateleiras;
- Para analisar padrões de navegação na web.
Algoritmos populares: Apriori, Euclat, FP-growth.
A aprendizagem por regras de associação inclui todos os métodos para analisar carrinhos de compras, automatizar estratégias de marketing e outras tarefas relacionadas a eventos. Quando se tem uma sequência de algo e quer-se encontrar padrões nela – tenta-se associação.
Digamos que um cliente entre um um mercado, pegue um pacote de seis cervejas e vá para o caixa. Deveria colocar amendoins no caminho? Com que frequência as pessoas compram estes dois itens juntos?
Sim, provavelmente funciona para cerveja e amendoim, mas que outras sequências podemos prever? Pode uma pequena mudança no arranjo de mercadorias levar a um aumento significativo nos lucros?
O mesmo vale para o comércio eletrônico. A tarefa é ainda mais interessante – o que o cliente vai comprar da próxima vez?
O aprendizado por regras parece ser o menos elaborado na categoria de aprendizado de máquina. Os métodos clássicos são baseados em uma visão frontal de todos os produtos comprados usando árvores ou conjuntos. Algoritmos só podem procurar por padrões, mas não podem generalizar ou reproduzi-los em novos exemplos.
No mundo real, todo grande varejista constrói sua própria solução proprietária, portanto não há revoluções acontecendo aqui.
2 – Aprendizagem por Reforço
“Jogue um robô em um labirinto e deixe-o encontrar uma saída”.
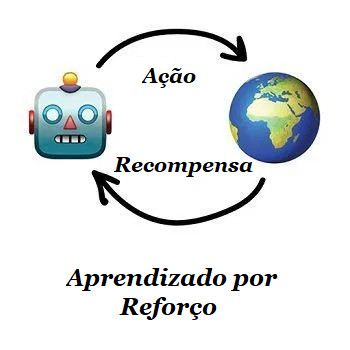
Usada nos dias de hoje para:
- Carros autônomos;
- Jogos;
- Automatizando a negociação;
- Gerenciamento de recursos corporativos.
Algoritmos populares: Q-Learning, SARSA, DQN, A3C, Genetic algorithm.
Agora chegamos a algo que se parece com inteligência artificial real. Em muitos artigos, o aprendizado por reforço é colocado entre o aprendizado supervisionado e o não supervisionado, mas eles não têm nada em comum!
O aprendizado por reforço é usado nos casos em que seu problema não está relacionado a dados, mas você tem um ambiente virtual ou real para interação, como um mundo de videogame ou uma cidade para carros autônomos.
O conhecimento de todas as regras de trânsito no mundo não ensinará o piloto automático a dirigir nas estradas.
Independentemente da quantidade de dados que coletarmos, ainda não poderemos prever todas as situações possíveis. É por isso que seu objetivo é minimizar o erro, não prever todos os movimentos.
Veja o exemplo abaixo de redes neurais jogando Mário.
Sobreviver dentro de um ambiente é a idéia central do aprendizado por reforço. Através de um sistema de punições e recompensas o robô é ensinado da mesma maneira que uma criança aprende.
Um truque eficaz para construir um modelo de carros autônomos é construir uma cidade virtual e deixar o self-driving-car aprender primeiro todos os seus truques. É exatamente assim que treinamos pilotos automáticos no momento. Crie uma cidade virtual baseada em um mapa real, preencha com pedestres e deixe o carro aprender a matar o menor número possível de pessoas.
Quando o robô está razoavelmente confiante neste “GTA artificial”, é liberado para testar nas ruas reais. Diversão!
Pode haver ainda duas abordagens diferentes – com base em modelo e sem modelo.
Baseado em modelo significa que o carro precisa memorizar um mapa ou suas partes. Essa é uma abordagem bastante desatualizada, pois é impossível para o pobre carro autônomo memorizar o planeta inteiro.
No aprendizado sem modelo, o carro não memoriza todos os movimentos, mas tenta generalizar situações e agir racionalmente enquanto obtém uma recompensa máxima.
Lembra das notícias sobre a IA derrotando um dos melhores jogadores no jogo Go? Um pouco antes deste feito foi provado que o número de combinações neste jogo é maior que o número de átomos no universo.
Isso significa que a máquina mesmo sem se lembrar de todas as combinações, ainda assim, venceu no Go (como aconteceu no xadrez). A cada turno, ela simplesmente escolhia a melhor jogada para cada situação, superando o jogador humano ao final.
Essa abordagem é o conceito central por trás do Q-Learning e seus derivados (SARSA e DQN). ‘Q’ no nome significa “Qualidade”, pois um robô aprende a executar a ação mais “qualitativa” em cada situação e todas as situações são memorizadas como um simples processo markoviano

Essa máquina pode testar bilhões de situações em um ambiente virtual, lembrando quais soluções levaram a uma maior recompensa. Mas como ela pode distinguir situações já vistas anteriormente de uma outra completamente nova?
Se um carro autônomo está em uma estrada e o semáforo fica verde – isso significa que pode ir agora? E se houver uma ambulância correndo por uma rua próxima? A resposta hoje é “ninguém sabe”. Não há resposta fácil. Os pesquisadores estão constantemente pesquisando, mas enquanto isso, apenas encontram soluções alternativas.
Alguns codificariam manualmente todas as situações que os permitiam resolver casos excepcionais, como o Problema de Trolley. Outros se aprofundariam e deixariam as redes neurais fazer o trabalho de descobrir isso. Isso nos levou à evolução do Q-learning, chamado Deep Q-Network (DQN). Embora seja muito bom, não é uma bala de prata.
O aprendizado por reforço para uma pessoa comum pareceria uma inteligência artificial real. Porque faz-se pensar, esta máquina está tomando decisões em situações da vida real! Este tópico está no topo agora, avançando com um ritmo incrível.
Off-Topic. Há alguns anos, algoritmos genéticos eram realmente populares. Trata-se de lançar um monte de robôs em um único ambiente e fazê-los tentar atingir a meta até que eles morram. Depois, escolhemos os melhores, cruzamos-os, modificamos alguns genes e executamos novamente a simulação. Depois de alguns bilhões de anos, teremos uma criatura inteligente. Provavelmente. Evolução no seu melhor.
Os algoritmos genéticos são considerados parte do aprendizado por reforço e possuem a característica mais importante comprovada pela prática de uma década: ninguém dá a mínima para eles.
A humanidade ainda não conseguiu chegar a uma tarefa em que seriam mais eficazes do que outros métodos. Mas eles são ótimos para experiências de estudantes e deixam as pessoas entusiasmadas.
3 – Método Conjuntos (ensemble)
“Um bando de árvores estúpidas aprendendo a corrigir erros umas das outras”
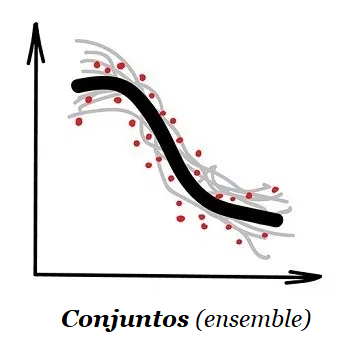
Usado nos dias de hoje para:
- Tudo o que se encaixa nas abordagens clássicas de algoritmos (mas funciona melhor);
- Sistemas de busca (★);
- Visão computacional;
- Detecção de objetos.
Algoritmos Populares: Random Forest, Gradient Boosting.
Finalmente chegamos aos métodos considerados mais vanguarda. Ensemble e Redes Neurais são os dois principais competidores na disputa para o caminho para a singularidade. Hoje eles estão produzindo os resultados mais precisos e são amplamente utilizados em produção.
Apesar de toda a eficácia, a idéia por trás disso é excessivamente simples. Pegando-se um monte de algoritmos ineficientes e forçando-os a corrigir os erros um dos outros, a qualidade geral de um sistema será maior do que os melhores algoritmos individuais.
Obter-se-á resultados ainda melhores com o uso dos algoritmos mais instáveis que estão prevendo resultados completamente diferentes com pouco ruído nos dados de entrada. A Regressão e Árvores de Decisão, por exemplo, são tão sensíveis que até mesmo um único dado fora do comum (outlier) nos dados de entrada pode levar os modelos a enlouquecerem.
Pode-se usar qualquer algoritmo que conhecemos para criar um Ensenble, que na tradução é “conjunto”. Basta jogar um monte de classificadores, apimentar com regressão e não se esqueça de medir a precisão. Por outro lado evita-se um Bayes ou kNN aqui. Embora “burros”, eles são realmente estáveis.
Em vez disso, existem três métodos testados em campo para criar Ensembles.
3.1 – Empilhamento (stacking)
A saída de vários modelos paralelos é passada como entrada para o último que toma uma decisão final. É como aquela garota que pergunta para as amigas se deve se encontrar com alguém, antes de tomar uma decisão final. Não somos tão diferentes desses algoritmos não é mesmo?
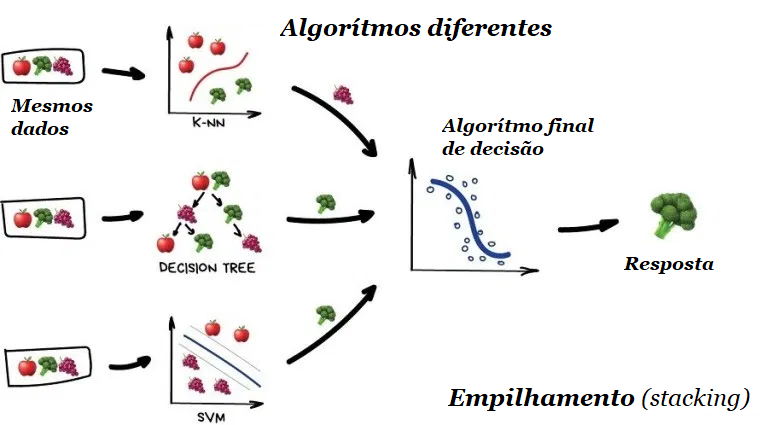
Ressalto aqui a palavra “diferente”. Misturar os mesmos algoritmos nos mesmos dados não faria sentido. A escolha dos algoritmos é totalmente de quem está resolvendo o problema. No entanto, para o modelo final de tomada de decisão, a regressão geralmente é uma boa escolha.
Na prática, o Stacking tem sido menos popular porque os dois próximos métodos estão fornecendo melhor precisão.
3.2 – Ensacamento (bagging)
Também conhecido como Bootstrap AGGregatING. É um método que usa os mesmos algoritmos, mas treina-os com diferentes subconjuntos de dados originais e no final usa apenas os resultados médios.
Dados em subconjuntos aleatórios podem se repetir. Por exemplo, de um conjunto como “1-2-3”, podemos obter subconjuntos como “2-2-3”, “1-2-2”, “3-1-2” e assim por diante. Usamos esses novos conjuntos de dados para ensinar o mesmo algoritmo várias vezes e, em seguida, prever a resposta final por meio da votação majoritária simples.

O exemplo mais famoso de Bagging é o algoritmo Random Forest que é simplesmente resultado de várias árvores de decisão, conforme ilustrado acima.
Quando se abre o aplicativo de câmera do telefone e o vê desenhando caixas em volta do rosto das pessoas – provavelmente é o resultado do trabalho do Random Forest. As redes neurais seriam muito lentas para serem executadas em tempo real, por isso, o método de Bagging, neste caso, é o ideal.
Em algumas tarefas, a capacidade do Random Forest de executar em paralelo é mais importante do que uma pequena perda de precisão no reforço, por exemplo. Especialmente no processamento em tempo real. Quando falamos de Machine Learning, sempre temos um trade-off.
3.3 – Impulsionamento (boosting)
No método de Boosting, os algoritmos são treinados um a um sequencialmente. Cada algoritmo subsequente presta mais atenção aos pontos de dados que foram imprevisíveis pelo anterior. Esse processo ocorre até o resultado ser satisfatório.
Do mesmo modo que o método Bagging, usamos subconjuntos de nossos dados, mas desta vez eles não são gerados aleatoriamente. Agora, em cada subamostra, coletamos uma parte dos dados que o algoritmo anterior falhou ao processar
Assim, o novo algoritmo aprende a corrigir os erros do anterior.

A principal vantagem aqui é uma precisão de classificação muito alta. Os contras já foram destacados – não são processados de forma paralela, o que pode torná-lo não tão rápido. Entretanto, ainda assim, é mais rápido que as redes neurais.
Na verdade, é como uma corrida entre um caminhão de lixo e um carro de corrida. O caminhão pode fazer mais, mas se você quiser ir mais rápido, pegue um automóvel.
Se você quiser um exemplo real do Método de Boosting é só abrir o Facebook ou o Google e começar a digitar uma consulta de pesquisa. O resultado dessa pesquisa é trazido pelo Método Ensemble utilizando boosting.
4 – Redes Neurais e Aprendizagem Profunda
“Temos uma rede de mil camadas, dezenas de placas de vídeo, mas ainda não sabemos onde usá-la. Vamos gerar fotos de gatos!”.
Usado nos dias de hoje para:
- Substituição dos algoritmos de aprendizagem de máquina tradicionais;
- Identificação de objetos em fotos e vídeos;
- Reconhecimento e síntese de fala;
- Processamento de imagem, transferência de estilo;
- Maquina de tradução.
Arquiteturas Populares: Perceptron, Convolutional Network (CNN), Recurrent Networks (RNN), Autoencoders
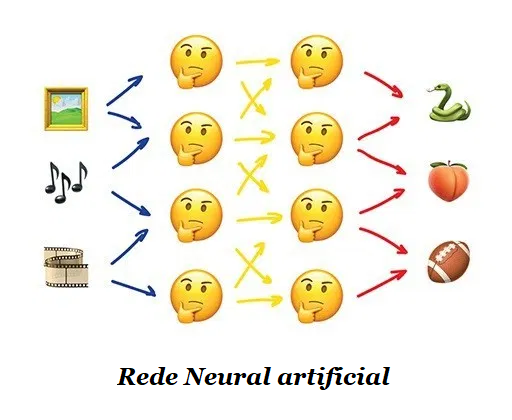
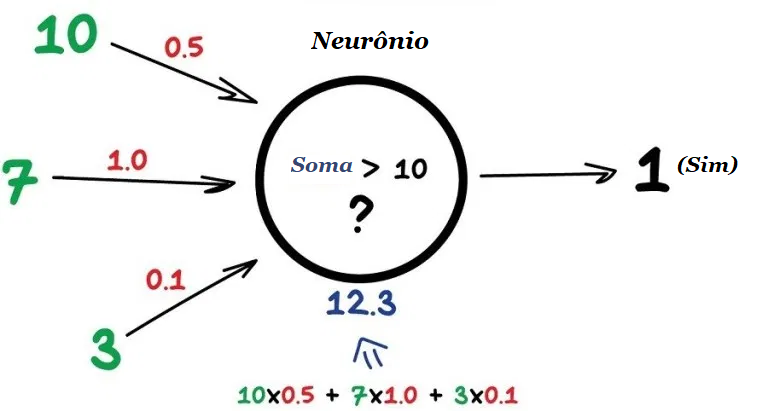
Qualquer rede neural artificial é basicamente uma coleção de neurônios artificiais e conexões entre eles. O neurônio é uma função com várias entradas e uma saída. Sua tarefa é pegar todos os números de sua entrada, executar uma função neles e enviar o resultado para a saída.
Aqui está um exemplo de um neurônio simples, mas útil na vida real: some todos os números das entradas e se essa soma for maior que N – dê “1” como resultado. Caso contrário – “zero”.
As conexões são como canais entre os neurônios. Eles conectam as saídas de um neurônio às entradas de outro, para que possam enviar dígitos um para o outro. Cada conexão possui apenas um parâmetro – peso. É como uma força de conexão para um sinal. Quando o número 10 passa por uma conexão com um peso 0,5, ele se transforma em 5.
Esses pesos dizem ao neurônio para responder mais a uma entrada e menos a outra. Os pesos são ajustados durante o treinamento – é assim que a rede aprende. Basicamente, é só isso.
Para impedir que a rede caia na anarquia, os neurônios são ligados por camadas, não aleatoriamente. Dentro de uma camada, os neurônios não estão conectados, mas estão conectados aos neurônios da camada “seguinte” e da camada “anterior”. Os dados na rede vão estritamente em uma direção – das entradas da primeira camada às saídas da última.
Se você lançar um número suficiente de camadas e colocar os pesos corretamente, obterá o seguinte: aplicando à entrada, digamos, a imagem do dígito manuscrito 4, pixels pretos ativam os neurônios associados, eles ativam as próximas camadas e assim por diante, até que finalmente acenda a saída encarregada dos quatro. O resultado é alcançado.
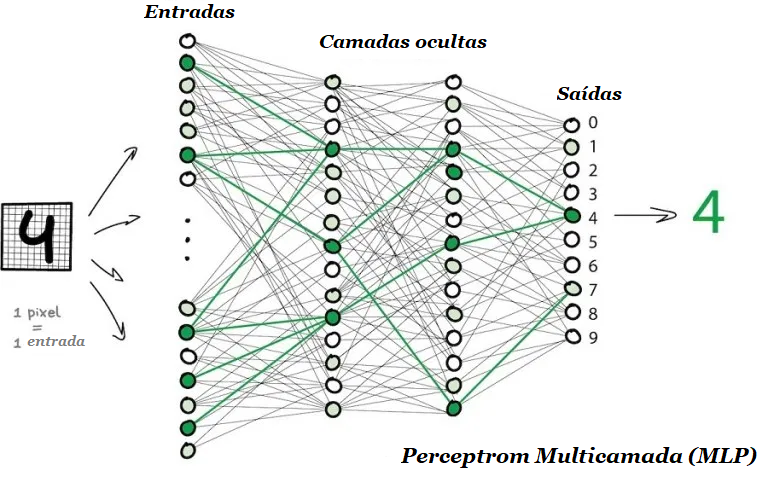
Uma rede que possui várias camadas que têm conexões entre todos os neurônios é chamada de perceptron (MLP), conforme imagem acima, e é considerada a arquitetura mais simples para um iniciante, embora não seja vista em produção.
Ao fazer a programação da vida real, ninguém escreve neurônios e conexões. Em vez disso, tudo é representado como matrizes e calculado com base na multiplicação de matrizes para melhor desempenho.
Este vídeo sobre isso, e sua sequência abaixo, descreve todo o processo de uma maneira facilmente digerível, usando o exemplo do reconhecimento de dígitos escritos à mão. Assista-o se você quiser entender melhor.
Depois que construímos uma rede, nossa tarefa é atribuir maneiras apropriadas para que os neurônios reajam corretamente aos sinais recebidos. Agora é a hora de lembrar que temos dados que são amostras de ‘entradas’ e ‘saídas’ apropriadas. Mostraremos à nossa rede um desenho do mesmo dígito 4 e informaremos ‘adapte seus pesos para que, sempre que você vir essa entrada, sua saída emita 4’.
Para começar, todos os pesos são atribuídos aleatoriamente. Depois que mostramos um dígito, ele emite uma resposta aleatória porque os pesos ainda não estão corretos e comparamos o quanto esse resultado difere do correto.
Então começa-se a atravessar a rede de saída para entrada e dizemos a todos os neurônios: “ei, você ativou aqui, mas você fez um péssimo trabalho, vamos dar menos atenção a essa e mais a essa outra, ok?”
Depois de centenas de milhares de ciclos desse tipo de ‘inferir / punir’, há uma esperança de que os pesos sejam corrigidos e ajam como pretendido. O nome científico dessa abordagem é Backpropagation. O engraçado foi que levaram vinte anos para criar esse método. Esse segundo vídeo descreve esse processo com maior profundidade, mas ainda é muito acessível.
Uma rede neural bem treinada pode falsificar o trabalho de qualquer um dos algoritmos descritos neste capítulo (e freqüentemente funciona com mais precisão). Essa universalidade é o que a tornou amplamente popular.
Finalmente, temos uma arquitetura do cérebro humano, eles disseram que precisamos montar muitas camadas e ensiná-las sobre todos os dados possíveis que esperavam. Então, o primeiro inverno da IA começou, depois se derreteu e outra onda de decepção ocorreu.
Descobriu-se que as redes com um grande número de camadas exigiam um poder de computação inimaginável na época.
Atualmente, qualquer PC com placas de vídeo Geforce supera os datacenters da época. Portanto, as pessoas não tinham nenhuma esperança de adquirir poder computacional como os que hoje temoa acesso e as redes neurais eram uma chatice enorme.
E então, dez anos atrás, o Deep Learning floresceu!
Há uma boa linha do tempo de aprendizado de máquina descrevendo a montanha-russa de esperanças e ondas de pessimismo.
Em 2012, as redes neurais convolucionais conquistaram uma vitória esmagadora na competição ImageNet que fez o mundo se lembrar repentinamente dos métodos de Deep Learning descritos nos anos 90 e que agora se tornam viáveis com nossas placas de vídeo!
As diferenças do Deep Learning das redes neurais clássicas estavam em novos métodos de treinamento que podiam lidar com redes maiores. Atualmente, apenas a teoria tentaria dividir qual aprendizado considerar profundo e não tão profundo.
Nós, como profissionais, usamos bibliotecas ‘profundas’ populares como Keras, TensorFlow e PyTorch, mesmo quando construímos uma mini-rede com cinco camadas. Só porque é mais adequado do que todas as ferramentas que vieram antes.
Nós apenas as chamamos de redes neurais.
Existe um artigo excelente chamado Neural Network Zoo, onde quase todos os tipos de redes neurais são explicadas brevemente.

Se gostou, por favor, compartilhe e não deixe de ler o post sobre Neurônios e Redes Neurais Artificiais.
Conte comigo em seus projetos. Sobre mim: aqui. Contato: aqui.
Um abraço, @neigrando
Referência
Este artigo trata-se da adaptação, redução e tradução, do post, em inglês, “Machine Learning for Everyone“.
Artigos relacionados
- Os 7 Padrões da Inteligência Artificial
- Neurônios e Redes Neurais Artificiais
- Para melhores decisões: Use Algoritmos
- Como as organizações podem mitigar os riscos da IA (HBR, pela PwC, 2021)
- A adoção da Inteligência Artificial pelas Empresas (do relatório O’Reilly de 2022)
- Modelo de Maturidade de Inteligência Artificial (proposto pelo Gartner)
- Lista de artigos sobre IA para Negócios
- …



