A equipe da IoT Analytics realizou uma extensa busca na internet por projetos de IA generativa conhecidos publicamente entre maio de 2022 e setembro de 2024 e reuniu todas as informações disponíveis para cada um dos 530 estudos de caso identificados.
Sobre os 530 projetos
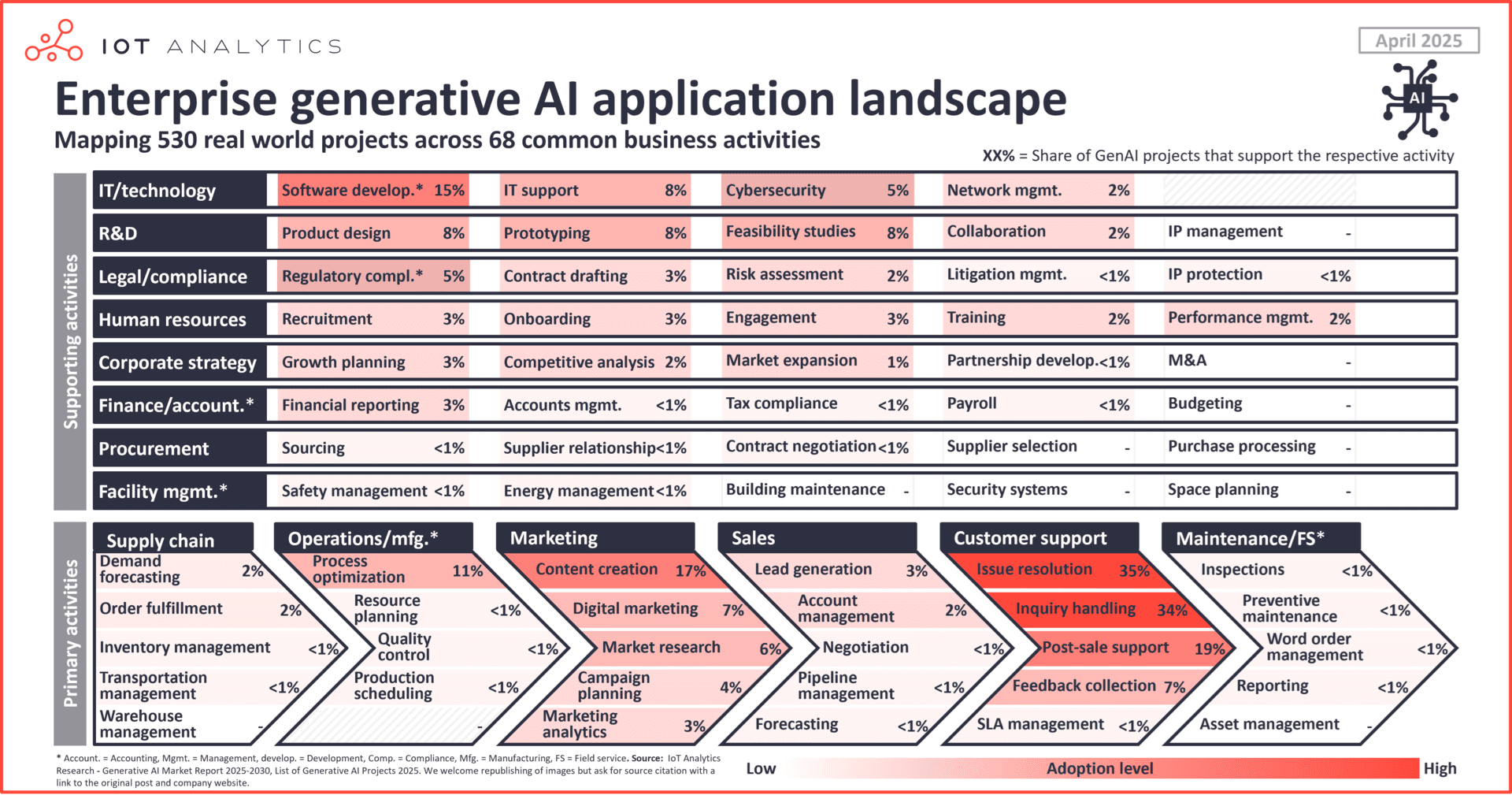
A principal atividade comercial impulsionada pela IA generativa é a resolução de problemas do cliente, aparecendo em 35% dos 530 projetos empresariais que a IoT Analytics identificou e publicou em sua Lista de Projetos de IA Generativa (publicada em fevereiro de 2025).
A IA generativa é amplamente aplicável em todos os departamentos. Cada um dos 14 departamentos diferentes analisados pela IoT Analytics para seu estudo possui atividade de IA generativa — em atividades primárias, como operações ou vendas, e atividades secundárias, como RH ou jurídico.
Departamento nº 1 a adotar IA generativa: Suporte ao cliente. Coincidindo com a resolução de problemas do cliente sendo a principal atividade empresarial, 49% dos projetos visavam aprimorar as funções de suporte ao cliente em geral. Outros departamentos que aparentemente estão fazendo uso intenso de IA generativa são marketing (27%) e TI (24%).
Setor nº 1 a adotar IA generativa: Tecnologia. O setor de tecnologia lidera a adoção, com 56% de participação nos projetos, com exemplos notáveis incluindo o assistente de IA Joule da SAP ou o Salesforce Einstein GPT. Muitos dos projetos de IA generativa implementados no setor de tecnologia resultam em produtos que são então vendidos para outras empresas. A manufatura (8%) é o segundo maior setor. Exemplos notáveis de projetos adotados em cada setor são o Siemens Industrial Copilot ou o projeto Coke Creations da Coca-Cola. Serviços profissionais (7%) vêm em terceiro lugar, com projetos como o KPMG KymChat ou o Accenture AI Navigator.
Região nº 1 em adoção de IA generativa: América do Norte. De uma perspectiva regional, os dados mostram que as organizações norte-americanas estão à frente na adoção de IA generativa, representando 56% da atividade total. Em seguida, vêm as empresas da região EMEA (27%) e as da região APAC (15%).
Estas são apenas algumas estatísticas de alto nível da lista de projetos de IA generativa. Abaixo, a equipe de análise de IoT analisa em detalhes as 10 principais aplicações corporativas de IA generativa, classificadas por frequência de adoção nos 530 projetos. Cada aplicação representa uma atividade empresarial diferente que se beneficia da IA generativa.
Definição de IA generativa
IA generativa é um tipo de inteligência artificial que utiliza técnicas de aprendizado profundo para gerar novos textos, códigos, imagens, áudios, vídeos ou outras formas de mídia. Ela se baseia em modelos treinados para analisar padrões e estruturas em grandes conjuntos de dados e usar essa análise para produzir novos resultados com características semelhantes.
As 10 principais aplicações de IA generativa
1. Resolução de problemas para suporte ao cliente – 35% dos projetos
Resolução de problemas refere-se ao tratamento de tickets de suporte recebidos, reclamações ou problemas relatados pelos clientes sobre seus produtos ou serviços. A IA generativa pode classificar, encaminhar e até mesmo responder automaticamente aos problemas dos usuários — geralmente em vários idiomas e canais.
Impacto nos negócios
Automatizar o suporte ao cliente com IA generativa pode ajudar a melhorar KPIs como tempo médio de resolução, taxa de resolução no primeiro contato, satisfação do cliente e custo de suporte por ticket. Ao reduzir a triagem manual e permitir respostas mais rápidas, as empresas relatam melhorias no tempo de resposta em até 80%, enquanto lidam com volumes maiores de tickets sem aumentos proporcionais de pessoal.
Além disso, o suporte com tecnologia de IA pode operar 24 horas por dia, 7 dias por semana e em vários idiomas, permitindo um serviço consistente em todas as regiões e fusos horários. Com o tempo, os adotantes esperam que isso leve a uma maior fidelidade do cliente, redução da rotatividade e economias substanciais de custos — especialmente para organizações com operações de clientes em larga escala.
Exemplo: Agente de atendimento de IA da Klarna
Em janeiro de 2024, a fintech sueca Klarna implantou um agente de atendimento ao cliente generativo baseado em IA e com tecnologia OpenAI, que supostamente resolveu a carga de trabalho equivalente a 700 agentes de suporte. O agente da Klarna agora lida com consultas em 23 mercados e, de acordo com a empresa, oferece suporte mais rápido e 24 horas por dia, além de contribuir para a redução de custos e ganhos de eficiência.
2. Tratamento de consultas para suporte ao cliente – 34% dos projetos
O tratamento de consultas envolve responder às solicitações de informações dos clientes, como solicitações de informações sobre produtos, detalhes de preços, status de pedidos ou explicações sobre serviços.
A IA generativa pode automatizar essas tarefas, permitindo que os agentes de suporte ao cliente se concentrem em questões mais urgentes.
Impacto nos negócios
Ao automatizar consultas padrão, as empresas podem desviar tickets de agentes ao vivo, liberando-os para se concentrar em casos mais complexos. Isso ajuda a reduzir os tempos de resposta, diminuir as pontuações de esforço do cliente e aumentar a satisfação. As respostas baseadas em IA podem ser adaptadas ao contexto do cliente (por exemplo, pedidos anteriores), melhorando a precisão e o valor percebido.
Exemplo: Assistente de consulta automatizado da Kuka
Em abril de 2023, a KUKA, fornecedora global de soluções de automação, trabalhou com a Empolis, uma empresa, para desenvolver a prova de conceito — e adotar — o assistente virtual de IA generativa da Empolis, chamado Empolis Buddy. Desenvolvido usando o Amazon Bedrock da AWS, o Empolis Buddy utiliza grandes modelos de linguagem para acessar e consultar documentação extensa, incluindo procedimentos operacionais padrão e manuais de fabricação.
3. Suporte pós-venda para suporte ao cliente — 19% dos projetos
O suporte pós-venda abrange tarefas como assistência na integração, orientação sobre o uso do produto, processamento de devoluções e gerenciamento de garantia. A IA generativa pode ser incorporada em centrais de ajuda, respondedores de e-mail ou sistemas de URA para orientar os clientes após a compra.
Impacto nos negócios
Aprimorar as experiências pós-venda ajuda a prevenir a rotatividade e aumenta as oportunidades de upsell. A IA generativa oferece suporte a um modelo de serviço proativo, orientando os usuários antes que os problemas surjam, personalizando o aconselhamento com base no histórico de compras e minimizando o atrito pós-venda. Isso pode reduzir o volume de tickets e melhorar o Net Promoter Score (NPS).
Exemplo: Assistente de IA da Telstra para agentes de atendimento
Em meados de 2023, a Telstra, uma operadora de telecomunicações australiana, desenvolveu duas ferramentas de IA generativa — Ask Telstra e One Sentence Summary — usando o Microsoft Azure OpenAI Service para aprimorar o suporte ao cliente após a ativação do serviço. Essas ferramentas ajudam os agentes a acessar rapidamente os detalhes da conta e do produto e a resumir interações anteriores, permitindo uma solução de problemas mais rápida e acompanhamentos mais personalizados. De acordo com a Telstra, as ferramentas reduziram os contatos de acompanhamento em 20%, com 90% de seus funcionários de atendimento ao cliente relatando economia de tempo e melhoria na qualidade do suporte pós-venda.
4. Criação de conteúdo para marketing – 17% dos projetos
Criação de conteúdo refere-se à geração de blogs, postagens em mídias sociais, textos publicitários, landing pages, campanhas de e-mail e comunicações internas. A IA generativa pode criar (ou ajudar a criar) esse conteúdo, aproveitando modelos de linguagem abrangentes que são ajustados para tom e relevância do assunto.
Impacto nos negócios
A IA pode reduzir o tempo de lançamento no mercado de campanhas e novos conteúdos (por exemplo, páginas da web) automatizando os primeiros rascunhos, adaptando as mensagens aos segmentos de público e garantindo a consistência da marca. Ela também reduz a dependência da agência e dimensiona os esforços de personalização sem exigir aumentos equivalentes de pessoal.
Exemplo: Assistente de marketing da NC Fusion
Em meados de 2023, a NC Fusion, uma organização esportiva juvenil sem fins lucrativos na Carolina do Norte, adotou o Microsoft Copilot no Dynamics 365 Customer Insights para aprimorar suas campanhas de marketing direcionadas, como a criação de e-mails e da jornada do cliente. Enfrentando desafios para escalar o alcance personalizado devido à limitação de recursos, a organização utilizou os recursos de IA generativa do Copilot para otimizar a criação de conteúdo e a segmentação do público. Essa integração permitiu que a NC Fusion reduzisse o tempo de elaboração de e-mails de 60 para 10 minutos, facilitando a implementação mais rápida de campanhas direcionadas, como a iniciativa “You do belong”, que visa incentivar meninas a permanecerem engajadas em esportes. Como resultado, a organização relatou um aumento de três vezes no engajamento do cliente, acrescentando:
5. Desenvolvimento de software para TI – 15% dos projetos
Desenvolvimento de software refere-se à geração de código, depuração, documentação de código e criação de casos de teste para software. Para auxiliar nessas tarefas, os desenvolvedores podem usar ferramentas generativas baseadas em IA incorporadas em ambientes de desenvolvimento integrados (IDEs), como GitHub Copilot, Amazon Q Developer e outros copilots proprietários, ou trabalhar com chatbots, como ChatGPT, Gemini ou Claude.
Impacto nos negócios
O suporte à IA reduz o tempo gasto em código boilerplate, documentação e tarefas de manutenção, permitindo que os desenvolvedores se concentrem em recursos de alto impacto. As organizações se beneficiam de lançamentos mais rápidos e menos bugs em produção.
Exemplo: Integração do Assistente de IA da JetBrains para programação
A JetBrains, fornecedora tcheca de ferramentas de programação com sede na Holanda, anunciou seu Assistente de IA para seu conjunto de IDEs em junho de 2023. Utilizando a API da OpenAI, este assistente auxilia os desenvolvedores gerando trechos de código, sugerindo refatorações e fornecendo explicações para segmentos de código. De acordo com a JetBrains, o Assistente de IA se tornou o produto de crescimento mais rápido da empresa, com 77% dos desenvolvedores relatando aumento de produtividade e 55% notando mais tempo para se concentrar em tarefas envolventes. A integração simplificou o processo de desenvolvimento, permitindo codificação e resolução de problemas mais eficientes.
6. Otimização de processos para operações – 11% dos projetos
A otimização de processos envolve a melhoria dos fluxos de trabalho para aumentar a eficiência, reduzir custos e aprimorar a qualidade dos resultados. Em operações, isso significa otimizar tarefas, eliminar gargalos e padronizar procedimentos. A IA generativa apoia isso
analisando dados (por exemplo, identificando atrasos nos registros de produção) e gerando recomendações ou documentação (por exemplo, elaborando POPs atualizados para manuseio de equipamentos) — ajudando as equipes a identificar melhorias mais rapidamente e implementá-las com mais eficácia.
Impacto nos negócios
A IA generativa permite a identificação mais rápida de ineficiências e agiliza melhorias de rotina, ajudando as organizações a reduzir custos operacionais, reduzir o esforço manual e acelerar a implementação. Ao automatizar tarefas como documentação e análise de dados, as empresas podem alcançar um desempenho mais consistente e obter ganhos mensuráveis em eficiência e ROI em suas operações.
Exemplo: Iniciativa de automação de documentos da Covered California
Em abril de 2024, a Covered California, um marketplace de seguros de saúde com sede nos EUA, implementou um processo generativo de verificação de sinistros com tecnologia de IA usando o Document AI do Google Cloud em colaboração com a Deloitte. A IA agora automatiza tarefas manuais recorrentes, como revisar documentos de elegibilidade, extrair dados relevantes e determinar o status da verificação. De acordo com a Covered California, essa automação melhorou a taxa de verificação de documentos de 28% a 30% para 84%, com expectativa de ultrapassar 95% após treinamento adicional — resultando em um processamento de sinistros mais rápido e um atendimento ao cliente aprimorado.
7. Suporte de TI – 8% dos projetos
Equipes de suporte de TI auxiliam em problemas técnicos comuns, como redefinições de senhas, solução de problemas de software e solicitações de acesso ao sistema. Essas tarefas podem ser confiadas à IA generativa para que as equipes de suporte de TI possam se concentrar em atingir as metas de TI da organização. Ferramentas baseadas em IA generativa são frequentemente incorporadas a help desks corporativos ou agentes virtuais.
Impacto nos negócios
Ao lidar com consultas repetitivas automaticamente, as organizações podem reduzir o backlog de tickets, diminuir os custos de suporte e liberar a equipe de TI para tarefas de maior complexidade. A IA também pode fornecer resoluções mais consistentes e precisas, baseando-se em documentação estruturada e casos históricos.
Exemplo: Assistente de suporte de TI com tecnologia de IA da Condor
Em 2024, a Condor, uma empresa brasileira de bens de consumo, desenvolveu um protótipo de IA generativa para aprimorar seu suporte interno de TI, em colaboração com a MadeinWeb, parceira da AWS, que supostamente foi construído em apenas algumas semanas. A Condor adotou a plataforma de IA generativa Charla, da MadeinWeb, que visa ajudar as empresas a usar o Amazon Bedrock em casos como assistentes virtuais. O assistente de IA da Condor foi treinado com base em seus tickets de TI históricos e documentação técnica e, de acordo com a Condor, o assistente fornece respostas precisas e contextualizadas às consultas dos funcionários, melhorando a eficiência do service desk e reduzindo os tempos de resposta.
8. Design de produto para P&D – 8% dos projetos
Design de produto é a ideação e o desenvolvimento de novos produtos. A IA generativa pode gerar variações de design, personalizar recursos e criar protótipos digitais com base em descrições textuais ou imagens de referência.
Impacto nos negócios
Ao automatizar aspectos do processo de design, as empresas podem explorar uma gama mais ampla de opções de design, adaptar produtos às preferências específicas do cliente e agilizar a transição do conceito para a produção.
Exemplo: Kit Inicial de Design de Produto com IA Generativa da Grid Dynamics
Em maio de 2023, a Grid Dynamics, uma empresa de engenharia digital sediada nos EUA, lançou seu Kit Inicial de Design de Produto com IA Generativa para apoiar varejistas, marcas e fabricantes na aceleração do design de produtos e no desenvolvimento de experiências digitais. O kit inclui modelos de referência e fluxos de trabalho que utilizam recursos de IA generativa de texto para imagem e imagem para imagem — permitindo que os usuários gerem, editem e reformulem conceitos de produtos a partir de prompts textuais ou visuais existentes. De acordo com a Grid Dynamics, essa abordagem melhora a ideação do design em estágio inicial, encurta os ciclos de prototipagem e oferece suporte a experiências de produtos mais personalizadas em escala.
9. Prototipagem para P&D – 8% dos projetos
A prototipagem envolve a criação de modelos funcionais ou simulações de produtos, serviços ou campanhas. As equipes de prototipagem podem usar IA generativa para executar essas tarefas, testar conceitos, coletar feedback e iterar designs com eficiência antes do desenvolvimento em larga escala.
Impacto nos negócios
Ao permitir a prototipagem rápida, as organizações podem validar ideias mais rapidamente, adaptar-se às mudanças do mercado e lançar inovações no mercado com mais agilidade.
Exemplo: Prototipagem de proteínas orientada por IA da Evozyne com a NVIDIA
A Evozyne, uma startup de biotecnologia sediada nos EUA, fez uma parceria com a NVIDIA, empresa americana de computação em IA e semicondutores, para desenvolver o modelo ProT-VAE, um sistema de IA generativa projetado para prototipar novas proteínas. Utilizando a estrutura BioNeMo da NVIDIA, o ProT-VAE
combina modelos de transformadores com autocodificadores variacionais para gerar milhões de sequências de proteínas em segundos. Essa abordagem permite modificações significativas — alterando metade ou mais dos aminoácidos de uma proteína em uma única iteração —, possibilitando a exploração de funções proteicas inteiramente novas. De acordo com Evozyne, esse método acelerou o processo de prototipagem de meses para semanas, facilitando o desenvolvimento de proteínas com potenciais aplicações no tratamento de doenças e na abordagem de desafios ambientais.
10. Estudos de viabilidade para P&D – 8% dos projetos
Estudos de viabilidade envolvem a avaliação da praticidade e do potencial de sucesso de projetos.
A IA generativa pode ajudar a simular cenários, analisar dados e prever resultados, auxiliando nos processos de tomada de decisão em diversos setores.
Impacto nos negócios
Ao fornecer simulações detalhadas e análises preditivas, as organizações podem tomar decisões informadas, reduzir riscos e alocar recursos de forma mais eficaz.
Exemplo: Modelagem de viabilidade de materiais baseada em IA da GenMat
Em março de 2023, a Quantum Generative Materials (GenMat), uma empresa americana de ciência de materiais, anunciou o desenvolvimento de modelos de IA generativa projetados para simular e avaliar novos materiais com mais eficiência. O sistema aplica modelagem generativa para avaliar a adequação potencial de um material para aplicações específicas — como energia, defesa ou aeroespacial — prevendo propriedades e comportamento sem testes extensivos de laboratório. De acordo com a empresa, a abordagem encurta as avaliações de viabilidade em estágio inicial, ajudando as equipes de P&D a priorizar quais materiais buscar e reduzindo o tempo e o custo normalmente associados à experimentação física.
Fonte: IoT Analytics – The top 10 enterprise generative AI applications – Based on 530 real-world projects – April 28, 2025.




