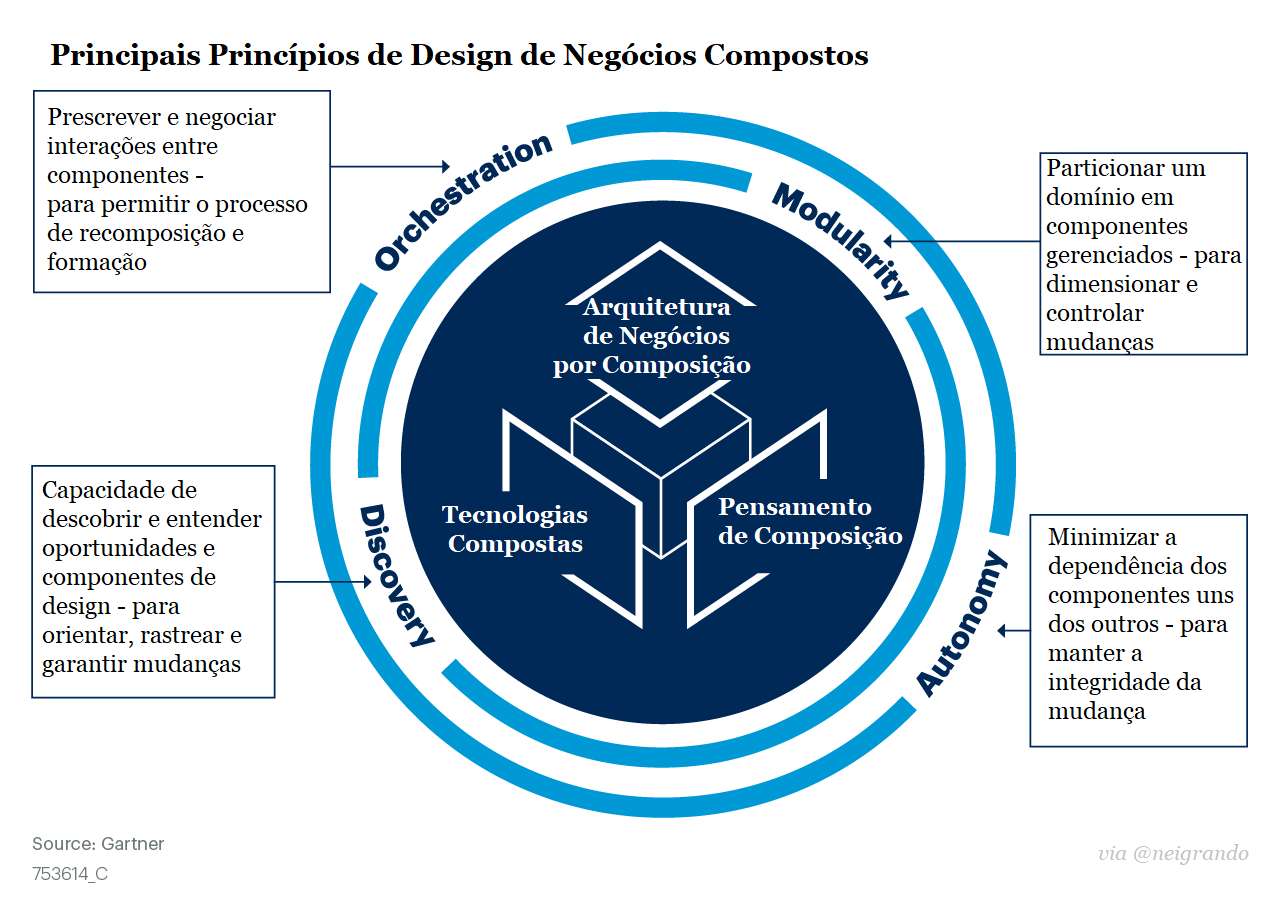
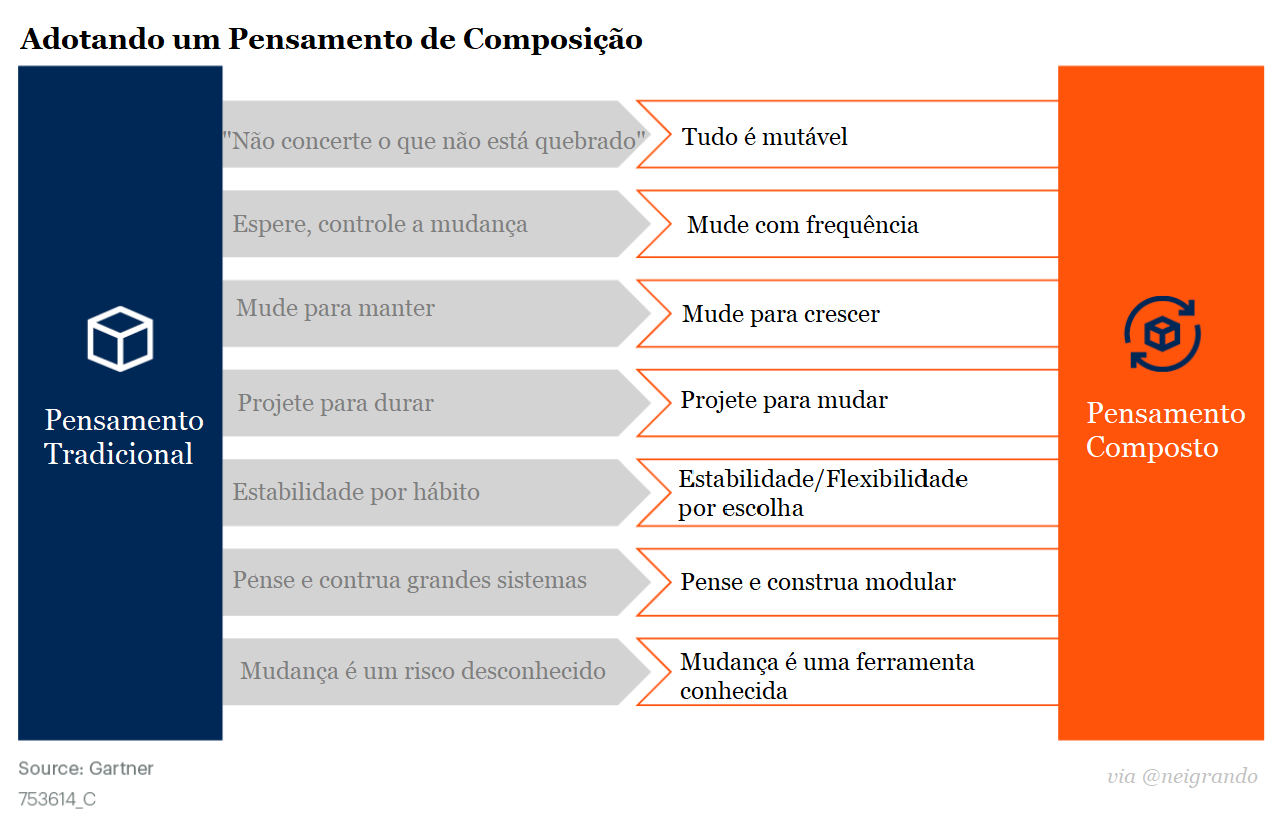
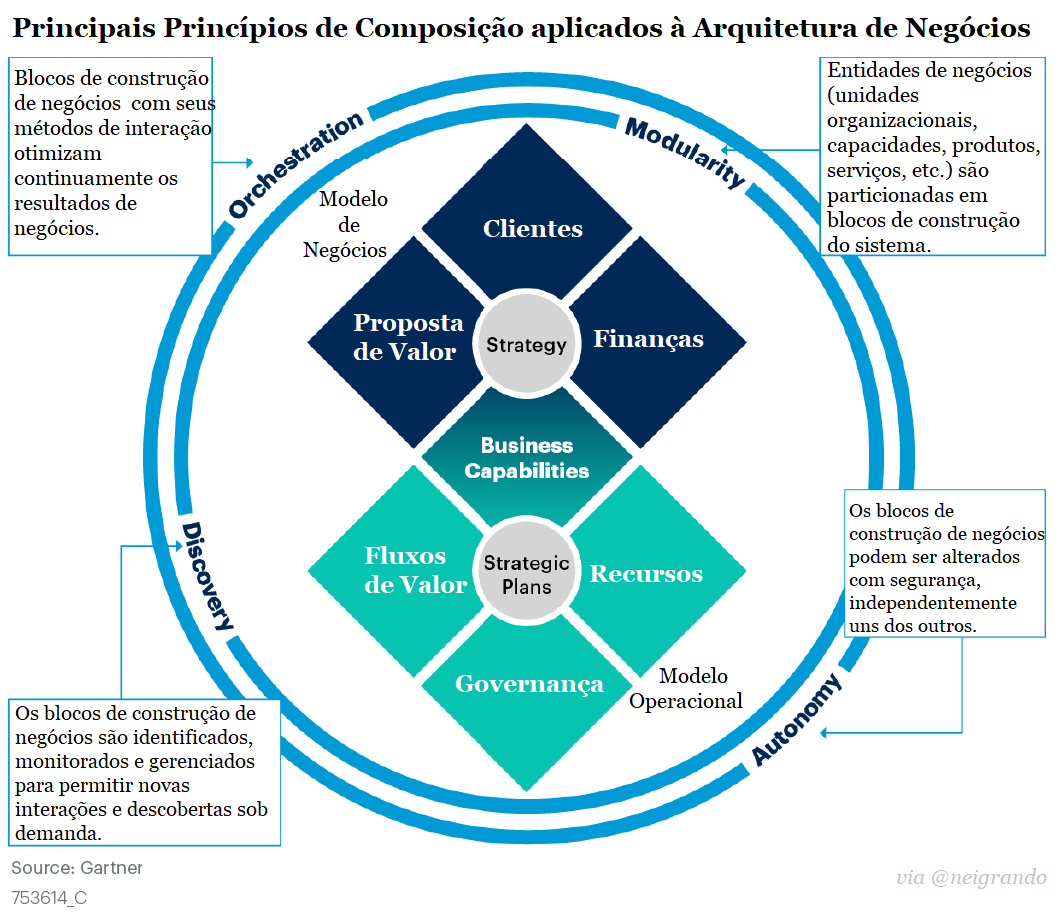
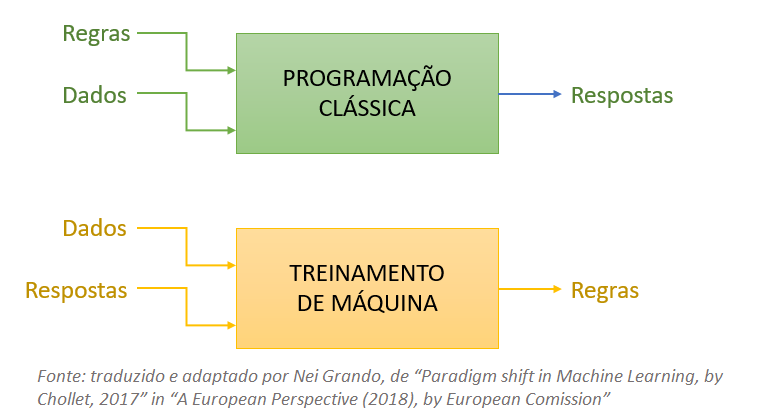
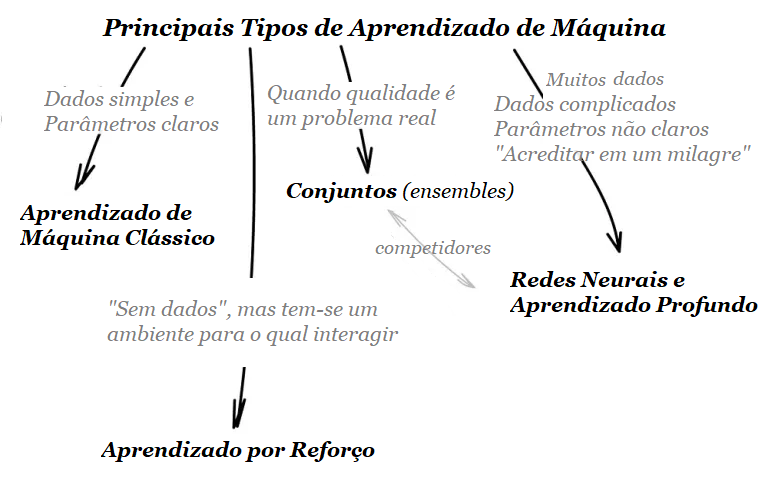
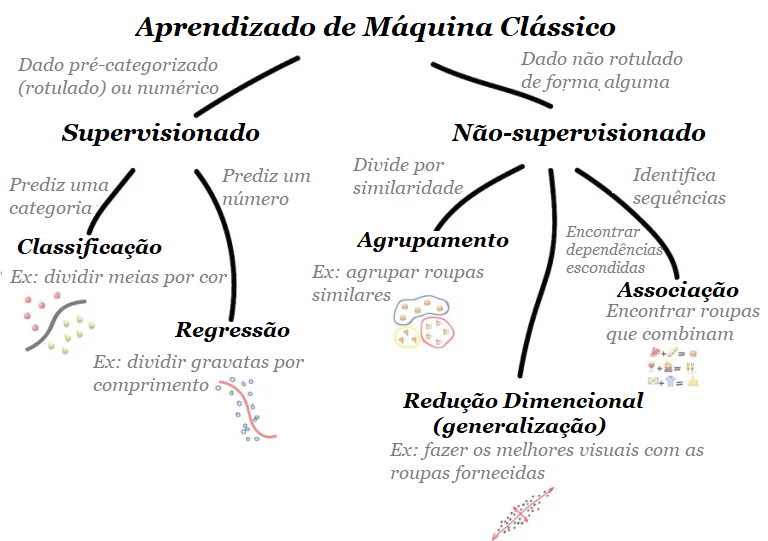
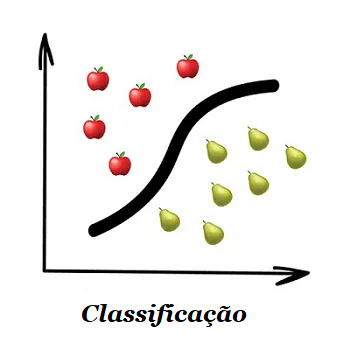
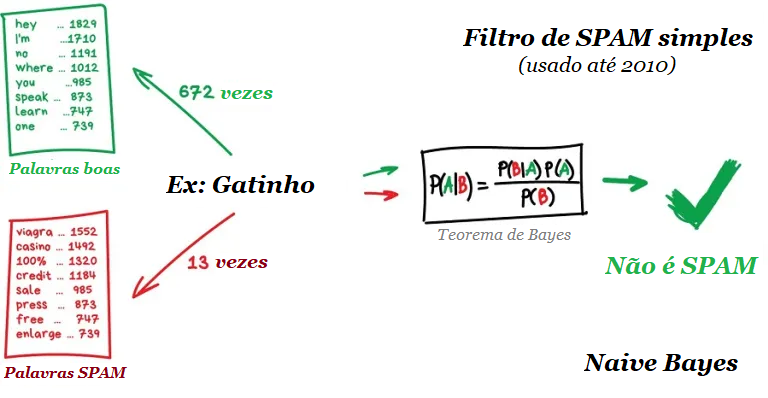
Em aproximadamente 30 anos desde que o primeiro navegador comercial da Internet foi criado, “ser digital” se tornou o mantra para a sobrevivência dos negócios. Os esforços digitais têm proliferado enormemente à medida que as empresas trabalham para acompanhar a inovação tecnológica – e o COVID-19 acelerou enormemente o ritmo.
No entanto, apesar de ter colocado tanta energia e investimento na digitalização, a maioria das empresas não ganhou uma vantagem competitiva. Na verdade, a digitalização pode até ter piorado as coisas, já que as empresas dedicaram cada vez mais seu dinheiro, tempo e energia simplesmente para tentar recuperar o atraso com seus rivais. Ser digital – seja ter um mecanismo sofisticado de e-commerce ou usar um poderoso pacote de gerenciamento de relacionamento com o cliente (CRM) – não é mais suficiente.
Não importa quantas iniciativas digitais você implemente, você não pode esperar construir uma vantagem competitiva real e de longo prazo sendo o mesmo que seus concorrentes ou fazendo o que você sempre fez, mesmo que agora esteja fazendo um pouco mais rápido e mais com mais eficiência do que antes.

Em vez disso, as empresas precisam ir além do digital. As principais empresas fazem isso começando com um grande desafio e, em seguida, construindo a diferenciação (digitalmente) nas capacidades que possuem. Eles obtêm seus recursos diferenciados da maneira certa e, em seguida, o fluxo de produtos, serviços, soluções e experiências movidos a energia digital segue naturalmente. Pense na capacidade de design da Apple, que permitiu que ela perturbasse todos os setores em que entrou. Ou considere a rápida inovação de sabores da Frito-Lay, que permite que ela produza rapidamente novos sabores quando detecta a demanda – por exemplo, um sabor de macarrão com queijo para Cheetos. A tecnologia digital desempenha um papel importante em todos esses recursos – mas esses recursos envolvem muito mais do que tecnologia. Eles exigem combinações dinâmicas de uma base de conhecimento, processos, tecnologias, dados, habilidades, cultura e modelos organizacionais que, juntos, permitem que as empresas criem valor de maneiras que outras não podem.
Então, qual é o melhor caminho a seguir? O livro, Beyond Digital, conduziu, ao longo de mais de dois anos, um esforço de pesquisa em uma dúzia de empresas cujas experiências coletivas contrastam fortemente com aquelas focadas apenas na digitalização. Aprendendo com os sucessos e fracassos dessas dezenas de organizações, identificamos sete imperativos de liderança para ir além do digital e moldar o futuro. Vamos olhar cada um por vez.
1. Reimagine seu lugar no mundo
Para ter sucesso neste novo ambiente, você deve olhar além de seu portfólio atual de negócios e produtos e determinar que valor criará e para quem. Você precisará ser muito mais ambicioso do que poderia imaginar há apenas cinco ou dez anos, graças em parte à evolução de plataformas digitais e ecossistemas poderosos dos quais agora pode participar. Qualquer que seja sua nova proposta de valor, certifique-se de ter identificado uma posição significativa que é exclusiva para você e impulsionada por suas capacidades.
Reconhecer fundamentalmente como você cria valor combina arte e ciência. Observar as tendências de dados e perguntar aos clientes o que eles desejam não é suficiente. Você precisa desenvolver seu próprio ponto de vista único sobre como o valor será avaliado e criado no futuro e quais recursos você precisará para cumprir essa proposição de valor. Seja claro sobre como as decisões de tecnologia apoiam seus recursos, em vez de jogar o jogo de investir em cada solução de tecnologia.
Dez anos atrás, a multinacional Philips sediada em Amsterdã tinha um amplo portfólio de negócios que incluía produtos eletrônicos de áudio e vídeo, iluminação e equipamentos médicos. No entanto, estava aquém das expectativas do mercado. Sob o comando do novo CEO Frans van Houten, a Philips decidiu se reinventar completamente. A empresa se reinventou como uma empresa de tecnologia de saúde, reunindo as amplas percepções e capacidades do consumidor da Philips, sua profundidade em tecnologias de dispositivos médicos e o poder dos dados e inteligência artificial (IA). Como explica Van Houten, “reconheci que as chances de transformarmos a iluminação e a saúde simultaneamente não eram tão grandes. E, então, fizemos uma escolha.”
A missão da Philips além do digital guiou a empresa por uma série de grandes mudanças que revolucionaram seu portfólio, modelo de negócios e cultura. Essas mudanças incluíram a saída de negócios que faziam parte da identidade da empresa – operações de TV, áudio e vídeo; a divisão de iluminação; e eletrodomésticos. Hoje, o foco da Philips como um player de tecnologia de saúde resultou em ganhos notáveis em lucratividade e valor para o acionista, o preço das ações tendo aumentado 82% nos cinco anos encerrados em 2020.
2. Abrace e crie valor por meio dos ecossistemas
Muitos dos problemas de hoje são tão grandes que nenhuma entidade pode resolvê-los por conta própria. Esses problemas podem ser enfrentados apenas por redes de empresas e instituições que trabalham juntas para um propósito comum. Por exemplo, pense sobre a necessidade de mobilidade das pessoas – que requer lidar com métodos de transporte públicos, compartilhados e privados; a infraestrutura; redes 5G públicas; fornecimento de energia; financiamento; regulamento; e muitos outros fatores.
A única maneira de as empresas prosperarem nesta era turbulenta é trabalhar com ecossistemas e aproveitar as capacidades que outros construíram para entregar suas próprias propostas de valor – e fazê-lo com rapidez, escala e flexibilidade.
Quando uma escassez de mão de obra surgiu na indústria de construção do Japão em 2013, a Komatsu tentou resolver o problema introduzindo máquinas de construção ICT (tecnologia da informação e comunicação) que usavam GPS, mapeamento digital, sensores e conexões de internet das coisas para aumentar a eficiência. Mas os líderes perceberam rapidamente que as novas máquinas não estavam resultando no aumento de produtividade esperado. A razão? Gargalos nos processos no canteiro de obras. Em um canteiro de obras de rodovia, por exemplo, a máquina ICT da Komatsu poderia remover e despejar 50% mais sujeira do que uma máquina convencional, mas as empresas de construção não conseguiram programar e contabilizar o número necessário de caminhões basculantes para remover a sujeira do local. Além disso, as construtoras não conseguiram prever com precisão o volume de sujeira que removeriam. Portanto, em 2015, a Komatsu criou uma divisão para focar em soluções amplas, aproveitando as capacidades específicas de uma série de outras empresas e fornecendo uma maneira de conectar digitalmente todas as pessoas e empresas envolvidas nas tarefas de construção e produção. Com tanto agora visível, as empresas em todo o ecossistema poderiam colaborar para aumentar a eficiência e a produtividade. No início de 2017, a Komatsu lançou uma plataforma aberta, Landlog, que tanto fornecedores quanto construtoras poderiam se conectar para tornar os locais mais inteligentes e seguros. Como resultado, para citar apenas um exemplo, os drones podem completar uma pesquisa de um canteiro de obras típico em quatro a seis horas, menos de duas semanas, e o Landlog pode então integrar os dados coletados pelos drones para programar escavadeiras automatizadas. Os clientes relatam serem capazes de concluir o trabalho de construção duas vezes mais rápido do que fariam usando as abordagens tradicionais, economizando dinheiro e reduzindo a pressão sobre os trabalhadores da construção sobrecarregados.
No final de 2020, a Komatsu apresentou sua plataforma orientada ao ecossistema para mais de 10.000 locais de construção no Japão e agora expandiu a proposta para outros países, incluindo Estados Unidos, Reino Unido, Alemanha, França e Dinamarca.
3. Construa um sistema de insights privilegiados com seus clientes
Os clientes sempre foram exigentes. Mas, à medida que os mercados se tornaram mais diversos, dinâmicos e complexos, as expectativas de serviço, consistência e confiança mudaram completamente. Ao mesmo tempo, as oportunidades de coleta, armazenamento e análise de dados explodiram. E a única ferramenta que as empresas utilizam para conhecer seus clientes, a pesquisa de mercado, não está equipada para esse novo mundo.
Como mostra o ecossistema Komatsu, construir um sistema de percepções privilegiadas – percepções que você, exclusivamente, tem sobre seus clientes – requer muito mais do que comprar pesquisas de mercado. Exige que as empresas estabeleçam uma base sólida de propósito e confiança. Afinal, os clientes compartilham suas informações mais úteis e privadas com você, mas apenas se o valor que você oferece em troca repercutir neles e eles confiarem em você para fazer um bom uso de seus dados. Com base nessa base, as empresas podem se concentrar em resolver os problemas mais importantes de seus clientes (por exemplo, ouvindo os clientes em todo o espectro de suas interações). Você pode usar os insights privilegiados obtidos para fortalecer sistematicamente suas propostas de valor, sistemas de recursos e produtos e serviços oferecidos.
Na verdade, obter percepções privilegiadas pode se tornar uma de suas capacidades mais importantes. Quanto melhores forem seus insights, mais você pode aumentar seu valor para os clientes. Quanto mais você melhora suas propostas de valor, mais confiança você gera ao cumprir suas promessas e mais os clientes se envolvem com você. Quanto mais os clientes se envolvem e confiam em você, mais você permanece conectado e relevante para eles – independentemente das mudanças que acontecem no mundo ao seu redor.
Em 2014, a Adobe, empresa de software com sede em San Jose, Califórnia, abandonou a venda de seus aplicativos amplamente usados (como Photoshop, Illustrator e InDesign) como produtos embalados, principalmente como CDs de vendedores terceirizados, e começou a oferecer aplicativos como soluções de software como serviço (SaaS) baseadas em nuvem por meio de assinatura direta. Essa mudança foi apenas o começo. A Adobe reconfigurou seu modelo operacional em torno dos dados recém-disponíveis e percepções do consumidor – e turbinou seus negócios. Antes da mudança, basicamente tudo que a Adobe sabia era quando um cliente registrava um produto. A mudança para o modelo SaaS deu à empresa a capacidade de ver como os clientes estavam usando seus aplicativos em tempo real.
A Adobe então reorientou muito de seu modelo de criação de valor – e estrutura organizacional, como uma próxima etapa lógica – em torno das percepções do cliente. A empresa percebeu que alguns aplicativos negligenciados estavam na verdade gerando um enorme valor para os clientes. Outros insights levaram as equipes a desviar recursos, oferecer novas experiências de integração e fornecer ajuda instantânea. A Adobe foi capaz de detectar que, digamos, um cliente do Photoshop estava ficando frustrado ao editar uma foto e sugeriu um filtro, outra correção ou um tutorial.
Os líderes da Adobe creditam a maior parte do crescimento da receita da empresa, de US$ 5,9 bilhões em 2016 para US$ 12,9 bilhões em 2020, à sua capacidade de insights baseados em dados. E o sucesso da Adobe no início de 2019 a levou a lançar a Adobe Experience Platform, que lhe permitiu vender seu sistema de insights para outras empresas, abrindo um novo fluxo de receita.
4. Torne sua organização orientada para resultados
A criação de valor ampliando alguns recursos de diferenciação requer um novo modelo de trabalho e equipe, dada a gigantesca elevação que alguns desses recursos exigirão à medida que você entrega uma proposta de valor mais ousada. Você não pode se safar tirando as pessoas de suas funções funcionais e pedindo-lhes que trabalhem juntas de 10 a 20% do tempo, ou por seis semanas ou seis meses (na famosa, mas geralmente frustrante equipe multifuncional). Em vez disso, você terá que construir equipes mais duráveis e orientadas para os resultados que reúnam a experiência, o conhecimento, a tecnologia, os dados, os processos e os comportamentos necessários de toda a organização.
Esse tipo de pensamento permitirá que você mude da velha organização funcional e fixa para um modelo de equipes orientadas a resultados que trabalham além das fronteiras organizacionais para fornecer suas capacidades. Essas equipes coexistirão com os escritórios corporativos, unidades de negócios, funções e serviços compartilhados, mas se tornarão cada vez mais elementos proeminentes da organização.
A divisão aeroespacial da Honeywell iniciou sua visão de equipes orientadas a resultados no final da década de 1990, quando os líderes começaram a pensar sobre como os avanços em digitalização, comunicações e conectividade podem criar oportunidades. Seus negócios de aviação fabricavam produtos como motores, freios, equipamentos de navegação e aviônicos. Eles também prestaram serviços como manutenção de aviões e software de informações de vôo. Demorou uma década para que as tecnologias subjacentes alcançassem a visão da Honeywell, mas em 2010 a Honeywell Aerospace estava mapeando como produtos e serviços poderiam ser reunidos como um negócio de “aeronaves conectadas”. O negócio agregaria significativamente mais valor ao cliente do que a soma de suas partes – oferecendo melhor energia e uso de combustível, manutenção preditiva, planejamento de voo mais preciso e informações meteorológicas crowdsourced em tempo real.
A Honeywell percebeu que uma grande reorganização de seus negócios de produtos e serviços de aviação seria necessária para reunir as pessoas, habilidades e capacidades certas. A empresa há muito construía aviões de maneira metódica, com funções que eram segregadas, mas agora precisava construir soluções que cruzavam as fronteiras entre motores, aviônicos e eletrônicos.
Uma mudança organizacional radical trouxe TI, análise de dados e pessoal de engenharia de suas funções domésticas para uma equipe e concedeu autoridade para ampla contratação daqueles com as novas habilidades necessárias. Conforme a transformação estava em andamento, novas equipes foram incumbidas de repensar como as ofertas legadas que existiam como produtos autônomos poderiam ser reinventadas para operar em um ambiente de rede mais amplo.
Hoje, a Honeywell Connected Aircraft é um negócio de US$ 800 milhões e é considerada por muitos analistas como a líder de mercado no espaço de aeronaves conectadas. A plataforma de eficiência de voo Honeywell Forge foi adotada por 128 companhias aéreas e mais de 10.000 aeronaves em todo o mundo em seu primeiro ano no mercado.
5. Inverta o foco da equipe de liderança
Assim como sua empresa precisa de um esforço estratégico para construir as capacidades de diferenciação certas, sua equipe de liderança precisará de novas habilidades e mecanismos para mudar para essa nova forma de criação de valor. Dê um passo para trás e comece a pensar a partir de uma folha em branco: Você tem os papéis certos? Você tem as pessoas certas? Você está se concentrando nas coisas certas? Você está conduzindo a mudança transformacional necessária ou gastando a maior parte do seu tempo respondendo às necessidades de curto prazo da organização? Vocês estão trabalhando juntos de forma eficaz?
Construir capacidades diferenciadas complexas e digitalizadas requer pensamento ousado, forte tomada de decisões e uma energia tremenda. Isso significa que sua equipe de liderança deve liderar de maneira diferente. Não é mais suficiente que sua equipe relate o que está fazendo e forneça seus pontos de vista sobre vários tópicos com base nas necessidades urgentes do momento. A equipe de liderança deve definir uma agenda agressiva e trabalhar em conjunto para realizar grandes coisas.
Quando a Eli Lilly teve problemas no final dos anos 2000, quando a proteção de patentes estava prestes a expirar para quatro medicamentos que representavam 40% da receita da empresa, o CEO John Lechleiter insistiu: “Vamos inovar para solucionar esse problema.” E o fizeram – em grande parte invertendo o foco da gestão.
Como parte de uma mudança no modelo operacional, Lechleiter instituiu mudanças maciças na equipe principal. Até 2009, a equipe de topo era conhecida como Comitê de Política, e nove dos 13 membros representavam funções, enquanto apenas três tinham responsabilidades operacionais. O desequilíbrio parecia ser um sintoma e uma causa de deficiências estratégicas e operacionais. Lechleiter criou um Comitê Executivo recém-nomeado e adicionou os chefes das cinco unidades de negócios à equipe, reduzindo o número de líderes com responsabilidades funcionais para cinco. No geral, oito dos 13 membros do Comitê Executivo eram novos naquela equipe e dois haviam sido contratados de fora. A mistura de experiências dos principais membros da equipe também mudou drasticamente.
“A dinâmica mudou completamente”, diz Stephen Fry, chefe de RH. “No antigo comitê, a maioria das pessoas acreditava que seu trabalho era ser o controle e o equilíbrio das pessoas que estavam realmente conduzindo o negócio. O novo comitê tinha uma maioria de pessoas com P&L e responsabilidade operacional, e a discussão na sala tornou-se muito mais voltada para a execução de negócios”.
Em 2016, a Lilly estava firmemente de volta ao caminho do crescimento lucrativo. Nos cinco anos seguintes, o preço das ações triplicou.
6. Reinvente o contrato social com seu pessoal
Envolver os funcionários na execução de uma transformação sempre foi importante, mas hoje está assumindo um significado totalmente novo. Dada a crescente dependência das capacidades que as pessoas ajudam a moldar e o ritmo acelerado das mudanças, a única maneira de ter sucesso é adotar uma “abordagem liderada pelo cidadão” – ter funcionários dentro da organização e do ecossistema contribuindo e inovando continuamente.
Para fazer com que as pessoas saibam para onde a empresa está indo, assegure-as de sua importância na formação do futuro da empresa. Quando as pessoas entenderem seu papel, envolva-as de forma mais significativa. Conectar seu propósito ao propósito da empresa; certifique-se de que eles podem contribuir e fazer parte da solução; oferecer-lhes um senso de comunidade; ajudá-los a desenvolver as habilidades e experiências de que precisam; e dar-lhes o tempo e os recursos necessários para construir as capacidades de diferenciação da empresa.
Um exemplo bem conhecido dessa abordagem é o da FedEx. Desde a sua criação, a FedEx colocou os funcionários no centro das inovações tecnológicas da empresa – e, para a FedEx, tem havido muitas, incluindo a primeira tecnologia de rastreamento em tempo real e o primeiro site a permitir que os clientes rastreiem as encomendas. Os executivos da empresa frequentemente associam a inovação da FedEx à sua filosofia People-Service-Profit (PSP) que remonta à década de 1970 — a ideia de que, se a empresa criar um ambiente de trabalho positivo para os funcionários, os funcionários, por sua vez, fornecerão melhor qualidade de serviço aos clientes, o que fazer com que os clientes queiram usar os produtos e serviços da FedEx, levando à lucratividade.
O elemento mais fundamental dessa filosofia é treinar e desenvolver talentos internos. O programa GOLD (Crescimento, Oportunidade, Liderança e Desenvolvimento) da FedEx, por exemplo, prepara os funcionários para uma possível sucessão na administração e envolve o aproveitamento da experiência e do conhecimento da alta administração, orientando os funcionários da linha de frente e profissionais que desejam gerenciamento. A empresa também oferece programas de treinamento em áreas como blockchain, realidade aumentada e virtual (AR/VR) e design thinking por meio do FedEx Institute of Technology. Além da sala de aula, a FedEx está usando tecnologia como VR para treinar novos contratados para trabalhos em campo, como trabalhos em depósitos – trabalhos que podem ser extenuantes e perigosos.
Há vários anos, a FedEx começou a explorar maneiras de desenvolver a filosofia People-Service-Profit para criar uma cultura que abrace e impulsione a mudança, diz Nik Puri, vice-presidente sênior de TI internacional da FedEx. Este trabalho envolveu enfatizar dois valores centrais: aprender e cuidar. O objetivo era ajudar os funcionários a liderar e se adaptar a qualquer forma de transformação. “A transformação digital está se beneficiando mais” do foco em aprender e cuidar, diz Puri.
A FedEx também está conectando o PSP com outra filosofia de gerenciamento – Quality-Driven Management (QDM), que busca a melhoria contínua, pensamento centrado no cliente, trabalho em equipe e eliminação de desperdícios. Ao reunir os dois programas com inovação de recursos, a empresa viu uma “capacidade exponencial” das equipes para adotar a mudança digital, diz Puri.
O impacto positivo desses movimentos pode ser encontrado na resposta da FedEx durante a pandemia, na qual investimentos em otimização e automação, big data, veículos autônomos e drones se uniram em novos recursos e soluções internas que ajudaram a empresa a atender a uma demanda sem precedentes por entrega de pacotes.
A natureza da criação de valor no mundo além do digital requer capacidades diferenciadas que são complexas e caras – e que dependem de pessoas para construí-las e fornecê-las. Por trás das implementações tecnológicas bem-sucedidas da FedEx estão os recursos criados e fornecidos pelos funcionários da empresa. Não importa quantos investimentos você possa fazer em novas tecnologias e negócios, se você não conseguir que seu pessoal os adote e os integre em seus recursos diferenciados, seus investimentos correm o risco de serem desperdiçados. De fato, quase por unanimidade, os líderes entrevistados durante a pesquisa da PwC disseram que não apenas aprenderam que precisavam se envolver com seu pessoal para ter sucesso em sua transformação, mas também desejaram ter feito muito mais cedo em sua jornada.
7. Interrompa sua própria abordagem de liderança
Apesar da singularidade de cada jornada, observamos um conjunto comum de características entre os líderes que transformaram a empresa, tanto no trabalho com líderes ao redor do mundo quanto em pesquisas para o livro. Essas características também se alinham bem com os seis paradoxos da liderança descritos no livro recente de nosso colega da PwC Blair Sheppard, Ten Years to Midnight.
Em suma, os líderes modernos precisam ser estrategistas e executores, conhecedores de tecnologia e profundamente humanos, hábeis em formar coalizões e fazer concessões enquanto são guiados por sua integridade. Ao mesmo tempo, eles precisam ser humildes e compreender suas limitações. Eles também precisam buscar inovação constantemente, ao mesmo tempo em que se baseiam no que são como empresa. E eles devem ter uma mentalidade global, bem como estar profundamente enraizados em suas comunidades locais.
Embora essas combinações possam parecer uma longa lista de paradoxos, encontramos muitas histórias de executivos que conseguiram conciliá-los. Por exemplo, Howard Schultz, ao retornar à Starbucks como CEO em 2008, mostrou a aparência de um executor estratégico. Mantendo sua visão original da Starbucks como um “terceiro lugar” além do escritório e de casa, Schultz se concentrou nos detalhes – acabando com o uso de sacos de grãos com sabor bloqueado, para que os aromas de café voltassem a encher as lojas enquanto os baristas retiravam os grãos das caixas e aterrá-los; realocar grandes máquinas de café expresso para que os clientes pudessem ver novamente os baristas fazendo bebidas; remover produtos da caixa registradora que, embora gerando receita, prejudicou o que ele viu como a experiência que distinguia a Starbucks de concorrentes como McDonald’s e Dunkin ’Donuts.
Estar ciente das características necessárias o ajudará a ser deliberado sobre seu desenvolvimento e a se cercar de pessoas que irão completar seu perfil de liderança.
Criando um sistema integrado de mudança
Trabalhar em todos os sete imperativos cria um verdadeiro sistema de interligação que tornará sua empresa adequada para os desafios que virão à medida que o mundo vai além do digital. Considere o que acontecerá se você negligenciar um deles. Quando você não tem certeza sobre o lugar da sua empresa no mundo, por exemplo, não terá um propósito claro que está enraizado em como você cria valor para os clientes. Você não terá uma estrela do norte para tomar decisões sobre quem está em seu ecossistema e como você deve fazer parceria com eles. Quando você não constrói um sistema de insights privilegiados com os clientes, não entende como seus desejos e necessidades evoluem – ou como você deve evoluir com eles. Quando você não torna sua organização orientada para resultados, seu pessoal terá dificuldade em trabalhar em silos e se esforçará para construir recursos multifuncionais diferenciados.
No entanto, abraçar qualquer um desses imperativos ajuda seus esforços nos outros. Trabalhar em um ecossistema, por exemplo, permite que você obtenha insights mais profundos sobre mais clientes de mais ângulos. Você também pode combinar forças com parceiros do ecossistema, oferecer maior valor aos clientes e ocupar um lugar mais ambicioso no mundo. E você fortalece as capacidades de sua equipe de liderança, dando-lhes a chance de ver intimamente como outras empresas funcionam. Em um espírito semelhante, reinventar o contrato social com seu pessoal e envolvê-los de forma significativa permite que contribuam para moldar para onde sua empresa está indo e como ela chegará lá.
Mas esses desafios não devem ser usados como desculpas para se manter os modelos de negócios atuais. Sem uma transformação de negócios mais fundamental, a digitalização é um caminho para lugar nenhum. Embora seja fácil digitalizar e alcançar os concorrentes, suas partes interessadas – acionistas, clientes e funcionários – exigem muito mais. Como Peter Drucker disse, “a administração está fazendo certo as coisas; liderança é fazer as coisas certas”. Agora é a hora de as equipes executivas se apresentarem, se romperem e se tornarem líderes na era digital.
O imperativo de dados e tecnologia
Conforme você vai além do digital, precisará certificar-se de abordar os dados e a tecnologia subjacentes necessários para oferecer suporte a seus recursos de diferenciação. Seus recursos de diferenciação precisarão ser alimentados por insights privilegiados, que, por sua vez, precisarão ser alimentados por dados, e esses dados precisarão ser suportados pela tecnologia certa para capturá-los e criar novos insights. Resumindo, você lutará para ter sucesso com a diferenciação baseada em recursos, sem uma estratégia de dados e tecnologia que ofereça suporte. Muitas empresas sofrem com os investimentos em dados e tecnologia que são isolados por função ou negócio e não estão claramente conectados à estratégia de criação de valor da empresa. Para ir além do digital, você precisará priorizar sua estratégia de dados e tecnologia e ser capaz de demonstrar de forma clara e tangível como isso possibilita diretamente o lugar de sua empresa no mundo e seu plano de criação e preservação de valor.
A tecnologia que ajuda as empresas a capturar dados e transformá-los em percepções existe e continua a ser inovada rapidamente. Soluções de planejamento de recursos empresariais (ERP) baseadas em nuvem, armazenamento sob demanda, sensores conectados, aprendizado de máquina e ferramentas de IA e muitas outras tecnologias projetadas para coletar, processar e analisar dados de forma rápida, flexível e criativa em abundância. O desafio geralmente é fazer escolhas entre a abundância de opções e sequenciar essas escolhas de forma que se reforcem mutuamente e levem a um impacto mensurável.
Ao considerar como moldar sua agenda de tecnologia e dados, oferecemos algumas perguntas que podem ajudá-lo a priorizar o que é certo para sua empresa:
- O investimento em tecnologia está contribuindo para o cerne de suas capacidades de diferenciação ou está atendendo a outras necessidades?
- O investimento está apoiando você na construção de amanhã ou garantindo o hoje? Qual será o impacto do investimento no lugar da sua empresa no mundo?
- Você pode medir e quantificar com clareza e honestidade o impacto nos negócios em termos de criação ou preservação de valor? O investimento se compensa de forma mensurável ou é baseado em premissas que podem ser validadas apenas no futuro? (Observação: se o investimento não puder se pagar comprovadamente e for baseado em suposições que você não pode validar hoje, é muito provável que não seja granular o suficiente e nem planejado bem o suficiente para ser aprovado).
- Você pode adquirir e reter o talento crítico para desenvolver essa tecnologia e torná-la relevante para o seu negócio? É essencial para suas capacidades de diferenciação construir a base de talentos dentro de sua organização?
- A capacidade de tecnologia de que você precisa já existe em algum lugar em seu ecossistema ou no mercado fornecedor mais amplo? Você pode aproveitar isso ao mesmo tempo em que protege suas capacidades de diferenciação e não coloca sua vantagem competitiva em risco?
- Você pode construir parcerias e relacionamentos confiáveis para executar com um equilíbrio entre velocidade e eficiência?
- Todas as partes interessadas que precisam mudar para perceber o valor de seus investimentos em tecnologia estão comprometidas com isso? Eles podem ser responsabilizados? Você tem o modelo de governança em vigor para garantir e fazer cumprir a responsabilidade individual e colaborativa?
- A sua organização e cultura estão prontas para a mudança? Você pode garantir que seu pessoal possa incorporar a tecnologia que você constrói?
Esta é uma lista inicial e certamente não exaustiva. No entanto, trabalhar essas questões pode ajudá-lo a abordar os fatores essenciais de sucesso necessários para moldar a estratégia de dados e tecnologia que apoiará sua visão além da digital.
Se gostou, por favor, compartilhe.
Conte comigo em seus projetos. Sobre mim: aqui. Contato: aqui.
Um abraço, @neigrando
Referência
Texto traduzido e adaptado com base no artigo original em inglês da PwC Strategy& “Seven imperatives for moving beyond digital”, by Paul Leinwand e Mahadeva Matt Mani (2021)